 进城务工人员小梅
进城务工人员小梅传输控制协议(TCP)无疑是所有现代网络的基本组成部分。但是,当在TCP本身中封装TCP隧道时,困难就开始出现了。在搜索引擎上,我们可以看到一篇写于早在2001年且被大量引用的文章《Why TCP Over TCP Is A Bad Idea》。
TCP最初设计了拥塞控制机制来缓解缓慢、延迟和不可靠网络所带来的问题。在TCP设计之初,消费者们没有快速的互联网网络。事实上,大多数消费者根本就上不了网;即便是他们能够上网,也都是通过不可靠的铜质电话线进行拨号连接,速度大概是300-1200 bps。与今天的标准相比,即使是大学和公司使用的网络也都是相对缓慢和不可靠。因此,TCP之类的协议被设计为通过使用各种拥塞控制机制来适应这种情况以在实现高网络性能的同时避免拥塞崩溃。这些机制包括定时器、发送数据确认和控制进入网络数据的速率。今天的现代TCP协议使用如下的四种算法来保持网络的性能性能:拥塞避免(congestion avoidance),快速恢复(fast recovery),快速重传(fast re-transmit)和慢启动(slow-start),这四点也是促成TCP协议整体成功的关键因素。
TCP divides the data stream into segments which are sent as individual IP datagrams. The segments carry a sequence number which numbers the bytes in the stream, and an acknowledge number which tells the other side the last received sequence number. [RFC793]
Since IP datagrams may be lost, duplicated or reordered, the sequence numbers are used to reassemble the stream. The acknowledge number tells the sender, indirectly, if a segment was lost: when an acknowledge for a recently sent segment does not arrive in a certain amount of time, the sender assumes a lost packet and re-sends that segment.
Many other protocols using a similar approach, designed mostly for use over lines with relatively fixed bandwidth, have the “certain amount of time” fixed or configurable. In the Internet however, parameters like bandwidth, delay and loss rate are vastly different from one connection to another and even changing over time on a single connection. A fixed timeout in the seconds range would be inappropriate on a fast LAN and likewise inappropriate on a congested international link. In fact, it would increase the congestion and lead to an effect known as “meltdown“.
For this reason, TCP uses adaptive timeouts for all timing-related parameters. They start at conservative estimates and change dynamically with every received segment. The actual algorithms used are described in [RFC2001]. The details are not important here but one critical property: when a segment timeouts, the following timeout is increased (exponentially, in fact, because that has been shown to avoid the meltdown effect, 即二进制指数避让).
The TCP timeout policy works fine in the Internet over a vast range of different connection characteristics. Because TCP tries very hard not to break connections, the timeout can increase up to the range of several minutes. This is just what is sensible for unattended bulk data transfer. (For interactive applications, such slow connections are of course undesirable and likely the user will terminate them.)
This optimization for reliability breaks when stacking one TCP connection on top of another, which was never anticipated by the TCP designers.
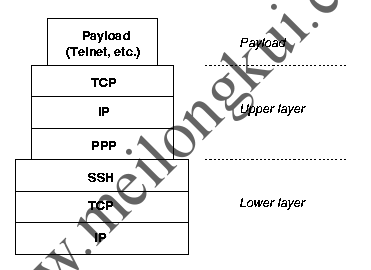
Stacking TCP
当来自外部TCP协议的拥塞控制干扰内部协议的拥塞控制时,问题就出现了,反之亦然。Note that the upper and the lower layer TCP have different timers. When an upper layer connection starts fast, its timers are fast too. Now it can happen that the lower connection has slower timers, perhaps as a leftover from a period with a slow or unreliable base connection.
Imagine what happens when, in this situation, the base connection starts losing packets. The lower layer TCP queues up a retransmission and increases its timeouts. Since the connection is blocked for this amount of time, the upper layer (i.e. payload) TCP won’t get a timely ACK, and will also queue a retransmission. Because the timeout is still less than the lower layer timeout, the upper layer will queue up more retransmissions faster than the lower layer can process them. This makes the upper layer connection stall very quickly and every retransmission just adds to the problem – an internal meltdown effect.
TCPs reliability provisions backfire here. The upper layer retransmissions are completely unnecessary, since the carrier guarantees delivery – but the upper layer TCP can’t know this, because TCP always assumes an unreliable carrier. 这并非是一个设计缺陷,因为当时协议的设计者甚至没有想到在自身内部封装TCP的想法。
随着时间的推移,2014年时网络的情况与2001年相比已经发生了翻天覆地的变化,也有人提出了《Under what circumstances is TCP-over-TCP performing significantly worse than TCP alone》的问题。这个问题涉及到的变量比较多,包括是否启用了SACK、传播时延、缓存大小等等,在《Understanding TCP over TCP: Effects of TCP Tunneling on End-to-End Throughput and Latency》这篇论文中进行了一定深度的探讨,其结论是:
In this paper, we have investigated effect of a TCP tunnel on the end-to-end TCP performance, and have shown the desired TCP parameter configuration for improving the end-to-end TCP performance. First, this paper has clearly shown that using a TCP tunnel usually degrades the goodput of the end-to-end TCP flow. However, it has also been found that in the network where the propagation delay is large, the goodput of the end-to-end TCP flow improves. We have shown that using the SACK option solves the problem of the decreased goodput of the end-to-end TCP flow. We have also shown that when the socket buffer size of the end-to-end TCP or the tunnel TCP is not large, the goodput of the end-to-end TCP flow degrades. We have also shown that the buffer size of the ingress router of the TCP tunnel should be large enough for preventing packet losses at the ingress router. 如此一来,我们的结论应该是:
1、大多数情况下由于两个重传机制的相互影响,TCP over TCP并不可取;
1、大多数情况下由于两个重传机制的相互影响,TCP over TCP并不可取;
2、如果要使用TCP over TCP则需要开启SACK;
3、在某些情况下TCP over TCP可能吞吐量更好(但时延并不一定好);
3、在某些情况下TCP over TCP可能吞吐量更好(但时延并不一定好);
此外,我们可能会怀疑TCP over UDP的“可靠性”问题;However, this discussion about unreliability of UDP is moot. Since we’re tunneling, there’s no difference between a TCP datagram lost on the open internet and a TCP datagram lost in a TCP tunnel or a TCP datagram lost in a UDP tunnel. All will be re-transmitted. It won’t re-request the UDP packets but it will re-request the tunneled TCP packet by tunneling that request within a new UDP packet. Of course, TCP-within-TCP means that both will be re-requested.
TCP is a protocol on top of IP. IP by itself is unreliable, so all the reliability is done at the TCP protocol level. If you use a UDP based VPN it usually encapsulates the IP into UDP, i.e. an unreliable protocol (IP) into another unreliable protocol (UDP). But since the reliability is implemented at the TCP level this does not matter, i.e. TCP over IP over UDP VPN is still a reliable protocol.
TCP is a protocol on top of IP. IP by itself is unreliable, so all the reliability is done at the TCP protocol level. If you use a UDP based VPN it usually encapsulates the IP into UDP, i.e. an unreliable protocol (IP) into another unreliable protocol (UDP). But since the reliability is implemented at the TCP level this does not matter, i.e. TCP over IP over UDP VPN is still a reliable protocol.
A problem with UDP tunnels are that they’re stateless, this makes it harder to secure at the firewall. Reply packets are no different than source packets. From a security perspective, TCP tunnels are easier.
参考资料:
1、http://sites.inka.de/bigred/devel/tcp-tcp.html
2、https://serverfault.com/questions/630837/under-what-circumstances-is-tcp-over-tcp-performing-significantly-worse-than-tcp
3、《Understanding TCP over TCP: Effects of TCP Tunneling on End-to-End Throughput and Latency》
4、https://tools.ietf.org/html/draft-cheshire-tcp-over-udp-00
5、https://security.stackexchange.com/questions/27806/whats-the-difference-between-vpn-over-tcp-vs-udp
6、https://i.stack.imgur.com/3BXBR.png、https://i.stack.imgur.com/yUPoY.png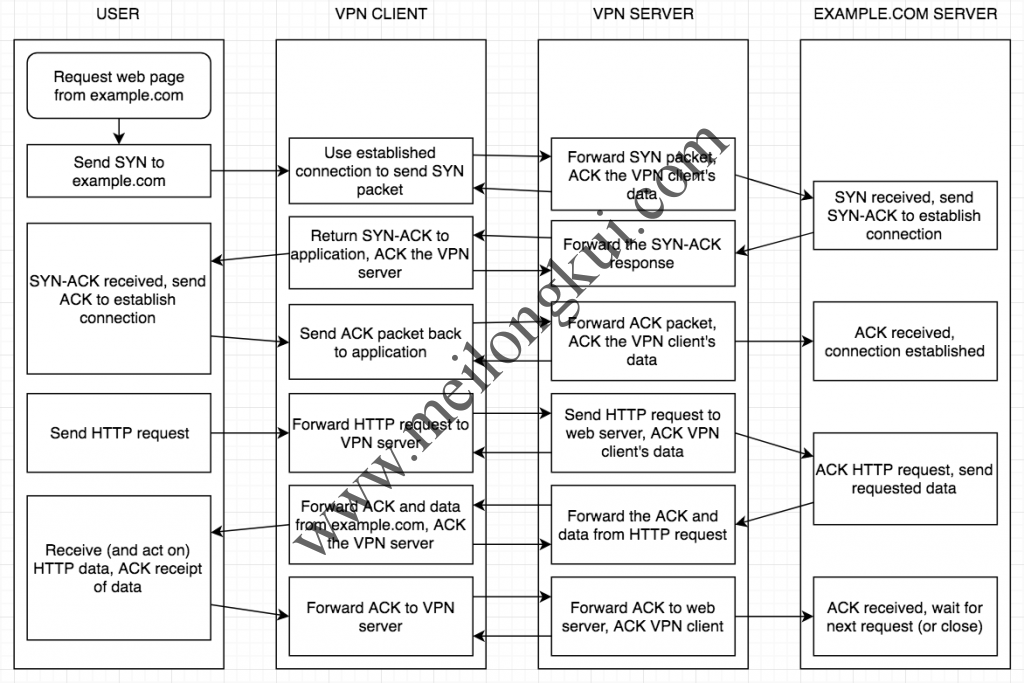
4、https://tools.ietf.org/html/draft-cheshire-tcp-over-udp-00
5、https://security.stackexchange.com/questions/27806/whats-the-difference-between-vpn-over-tcp-vs-udp
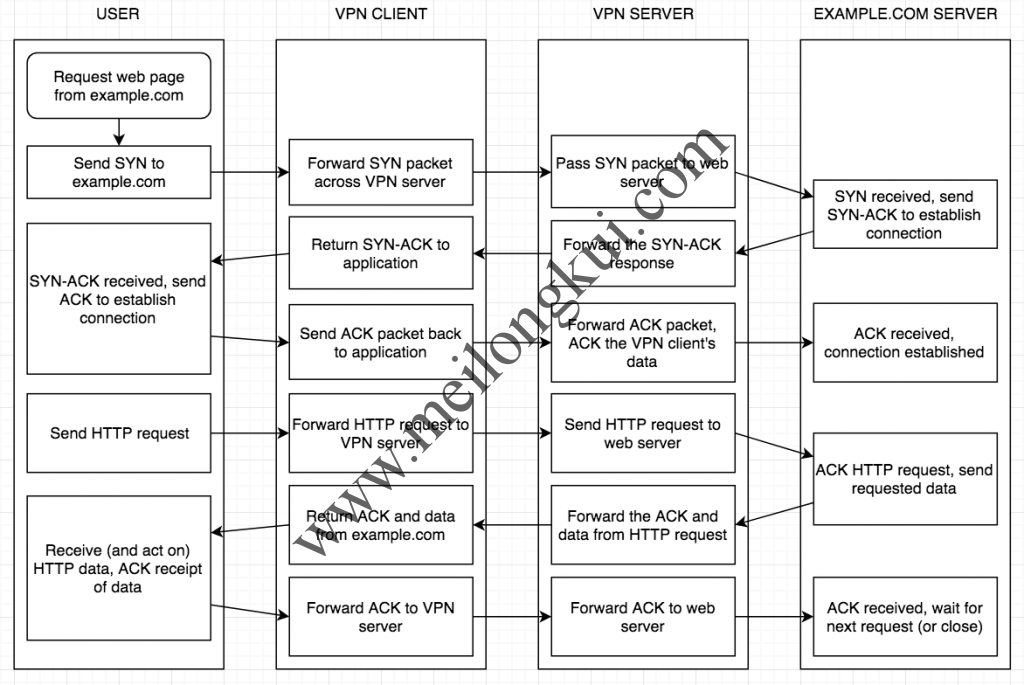
6、https://i.stack.imgur.com/3BXBR.png、https://i.stack.imgur.com/yUPoY.png
TCP over TCP(HTTP请求)示意
TCP over UDP(HTTP请求)示意
转载时请保留出处,违法转载追究到底:进城务工人员小梅 » 总结TCP over TCP是否是一个坏主意