 进城务工人员小梅
进城务工人员小梅摘要:本文指出了Mozilla Universal Charset Detection的一个Java实现(juniversalchardet)在处理短文本时的一个BUG、该BUG产生的原因及解决该BUG的方式。
一、问题现象
在《使用Java猜测或检测文本编码(Encoding detection),基于juniversalchardet和jchardet方案》一文中,指出了使用juniversalchardet检测某些文本编码是存在错误的情况。例如,考虑如下的字节数组(第一个数组是第二个数组的一部分,未加粗的为ASCII字符):
byte[] buf = new byte[] { -78, -35, -63, -15, -55, -25, -123, 94 };byte[] buf = new byte[] { 49, 48, 50, 52, -78, -35, -63, -15, -55, -25, -123, 94, 32, 116, 54, 54, 121, 46, 99, 111, 109, 46, 106, 112, 103 };
直接使用juniversalchardet时检测结果为错误的ISO-8859-7(实际应为GB18030):
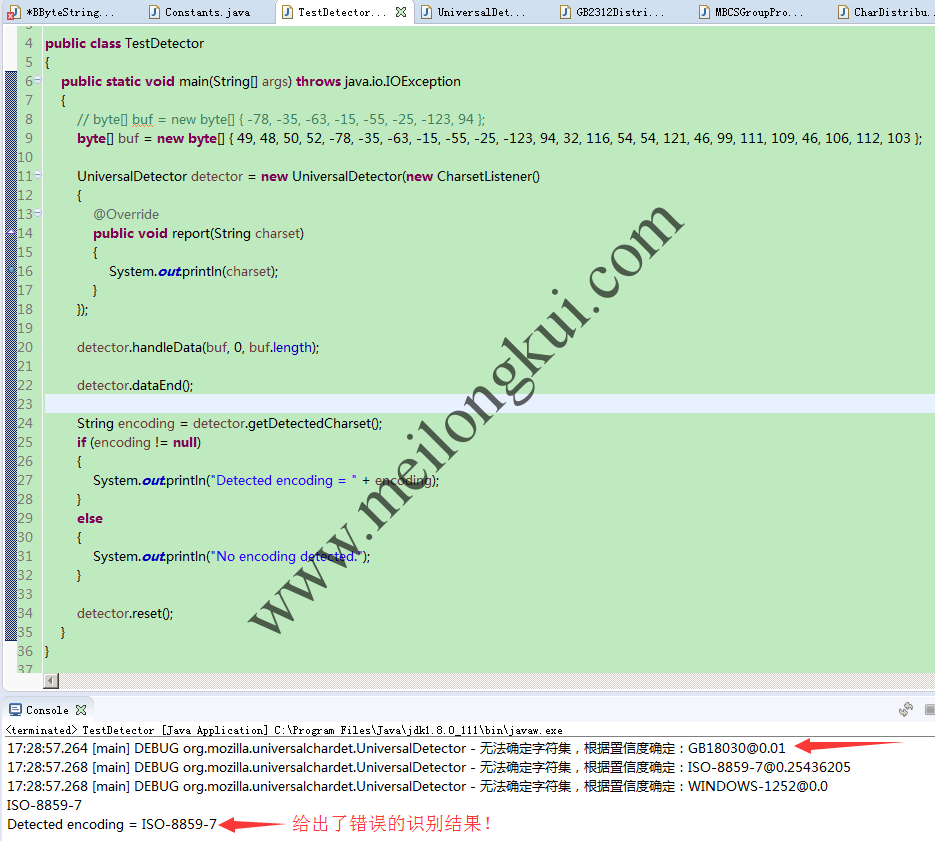
juniversalchardet识别中文编码错误
二、问题分析
该问题的产生原因与与juniversalchardet主要适用于篇幅较长的文本环境有关和基于统计原理有关。
org.mozilla.universalchardet.prober.distributionanalysis.CharDistributionAnalysis抽象类实现了《A composite approach to language/encoding detection》一文中基于统计规律的Character Distribution Method,继承CharDistributionAnalysis的主要有几个类:
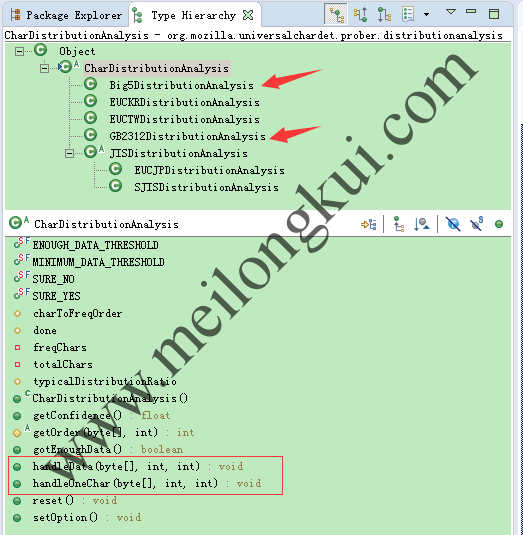
CharDistributionAnalysis抽象类的继承层次
该类中的关键之一在于通过handleOneChar方法统计有效字符及常用字符个数:
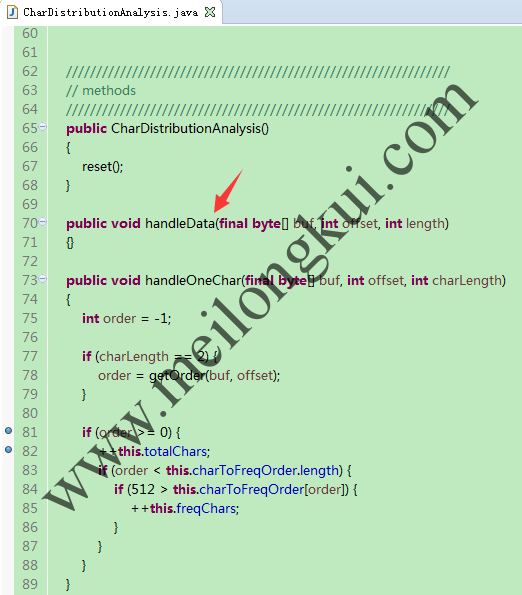
CharDistributionAnalysis抽象类的handleOneChar方法
并在需要使用置信率时,通过getConfidence方法计算置信率:
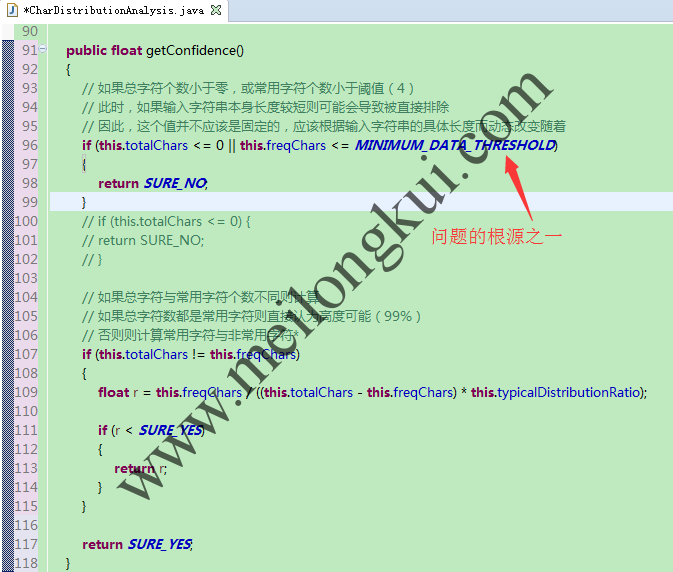
CharDistributionAnalysis的getConfidence方法
在handleOneChar方法中,调用了被子类Override的getOrder方法,该方法用于计算一个字符在所属字符集中的“区位码”(实际可以理解为CodePoint,就是一个字符所对应的索引)。有了这个区位码后,再查找对应*****DistributionAnalysis中记录了每一个字符分布频率排名的常量数组,即可判断出某一字符是否为有效的字符及是否为使用频率排序后靠前的512个常用字符。例如GB2312DistributionAnalysis:
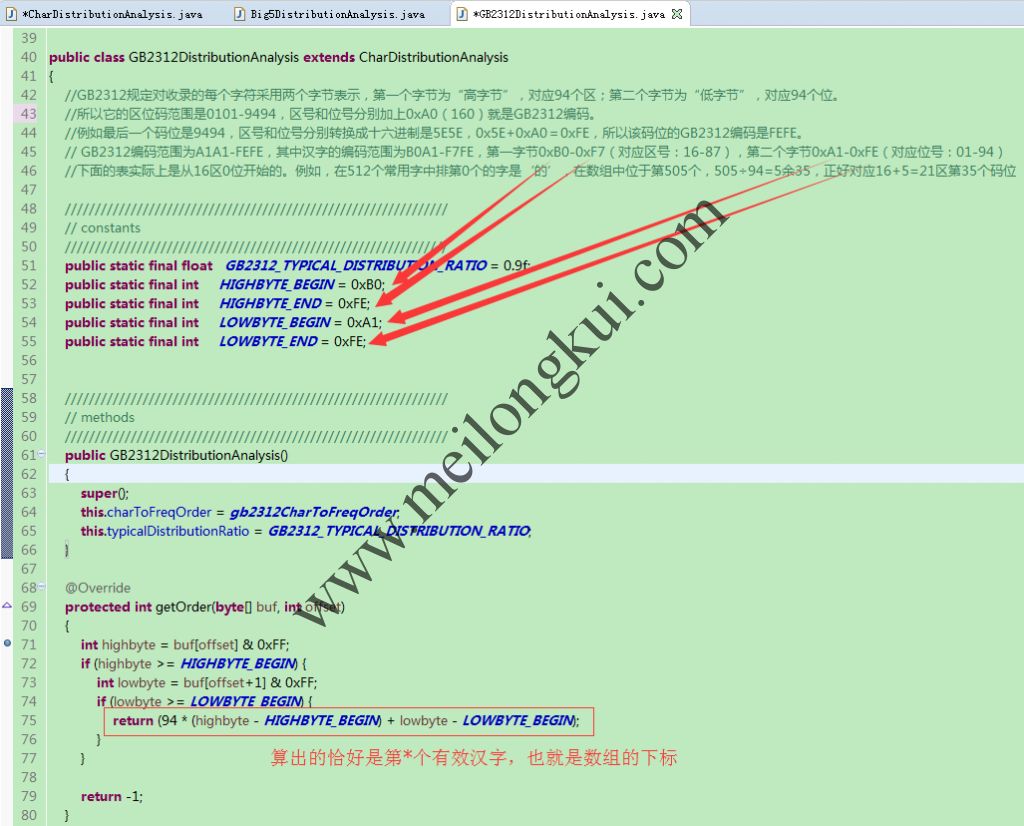
GB2312DistributionAnalysis的原理
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 |
第1区 code +0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +A +B +C +D +E +F A1A0 、 。 · ˉ ˇ ¨ 〃 々 — ~ ‖ … ‘ ’ A1B0 “ ” 〔 〕 〈 〉 《 》 「 」 『 』 〖 〗 【 】 A1C0 ± × ÷ ∶ ∧ ∨ ∑ ∏ ∪ ∩ ∈ ∷ √ ⊥ ∥ ∠ A1D0 ⌒ ⊙ ∫ ∮ ≡ ≌ ≈ ∽ ∝ ≠ ≮ ≯ ≤ ≥ ∞ ∵ A1E0 ∴ ♂ ♀ ° ′ ″ ℃ $ ¤ ¢ £ ‰ § № ☆ ★ A1F0 ○ ● ◎ ◇ ◆ □ ■ △ ▲ ※ → ← ↑ ↓ 〓 第2区 code +0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +A +B +C +D +E +F A2A0 ⅰ ⅱ ⅲ ⅳ ⅴ ⅵ ⅶ ⅷ ⅸ ⅹ A2B0 ⒈ ⒉ ⒊ ⒋ ⒌ ⒍ ⒎ ⒏ ⒐ ⒑ ⒒ ⒓ ⒔ ⒕ ⒖ A2C0 ⒗ ⒘ ⒙ ⒚ ⒛ ⑴ ⑵ ⑶ ⑷ ⑸ ⑹ ⑺ ⑻ ⑼ ⑽ ⑾ A2D0 ⑿ ⒀ ⒁ ⒂ ⒃ ⒄ ⒅ ⒆ ⒇ ① ② ③ ④ ⑤ ⑥ ⑦ A2E0 ⑧ ⑨ ⑩ ㈠ ㈡ ㈢ ㈣ ㈤ ㈥ ㈦ ㈧ ㈨ ㈩ A2F0 Ⅰ Ⅱ Ⅲ Ⅳ Ⅴ Ⅵ Ⅶ Ⅷ Ⅸ Ⅹ Ⅺ Ⅻ 第3区 code +0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +A +B +C +D +E +F A3A0 ! " # ¥ % & ' ( ) * + , - . / A3B0 0 1 2 3 4 5 6 7 8 9 : ; < = > ? A3C0 @ A B C D E F G H I J K L M N O A3D0 P Q R S T U V W X Y Z [ \ ] ^ _ A3E0 ` a b c d e f g h i j k l m n o A3F0 p q r s t u v w x y z { | }  ̄ 第4区 code +0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +A +B +C +D +E +F A4A0 ぁ あ ぃ い ぅ う ぇ え ぉ お か が き ぎ く A4B0 ぐ け げ こ ご さ ざ し じ す ず せ ぜ そ ぞ た A4C0 だ ち ぢ っ つ づ て で と ど な に ぬ ね の は A4D0 ば ぱ ひ び ぴ ふ ぶ ぷ へ べ ぺ ほ ぼ ぽ ま み A4E0 む め も ゃ や ゅ ゆ ょ よ ら り る れ ろ ゎ わ A4F0 ゐ ゑ を ん 第5区 code +0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +A +B +C +D +E +F A5A0 ァ ア ィ イ ゥ ウ ェ エ ォ オ カ ガ キ ギ ク A5B0 グ ケ ゲ コ ゴ サ ザ シ ジ ス ズ セ ゼ ソ ゾ タ A5C0 ダ チ ヂ ッ ツ ヅ テ デ ト ド ナ ニ ヌ ネ ノ ハ A5D0 バ パ ヒ ビ ピ フ ブ プ ヘ ベ ペ ホ ボ ポ マ ミ A5E0 ム メ モ ャ ヤ ュ ユ ョ ヨ ラ リ ル レ ロ ヮ ワ A5F0 ヰ ヱ ヲ ン ヴ ヵ ヶ 第6区 code +0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +A +B +C +D +E +F A6A0 Α Β Γ Δ Ε Ζ Η Θ Ι Κ Λ Μ Ν Ξ Ο A6B0 Π Ρ Σ Τ Υ Φ Χ Ψ Ω A6C0 α β γ δ ε ζ η θ ι κ λ μ ν ξ ο A6D0 π ρ σ τ υ φ χ ψ ω A6E0 ︵ ︶ ︹ ︺ ︿ ﹀ ︽ ︾ ﹁ ﹂ ﹃ ﹄ ︻ ︼ A6F0 ︷ ︸ ︱ ︳ ︴ 第7区 code +0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +A +B +C +D +E +F A7A0 А Б В Г Д Е Ё Ж З И Й К Л М Н A7B0 О П Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э A7C0 Ю Я A7D0 а б в г д е ё ж з и й к л м н A7E0 о п р с т у ф х ц ч ш щ ъ ы ь э A7F0 ю я 第8区 code +0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +A +B +C +D +E +F A8A0 ā á ǎ à ē é ě è ī í ǐ ì ō ó ǒ A8B0 ò ū ú ǔ ù ǖ ǘ ǚ ǜ ü ê ɑ ń ň A8C0 ɡ ㄅ ㄆ ㄇ ㄈ ㄉ ㄊ ㄋ ㄌ ㄍ ㄎ ㄏ A8D0 ㄐ ㄑ ㄒ ㄓ ㄔ ㄕ ㄖ ㄗ ㄘ ㄙ ㄚ ㄛ ㄜ ㄝ ㄞ ㄟ A8E0 ㄠ ㄡ ㄢ ㄣ ㄤ ㄥ ㄦ ㄧ ㄨ ㄩ A8F0 第9区 code +0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +A +B +C +D +E +F A9A0 ─ ━ │ ┃ ┄ ┅ ┆ ┇ ┈ ┉ ┊ ┋ A9B0 ┌ ┍ ┎ ┏ ┐ ┑ ┒ ┓ └ ┕ ┖ ┗ ┘ ┙ ┚ ┛ A9C0 ├ ┝ ┞ ┟ ┠ ┡ ┢ ┣ ┤ ┥ ┦ ┧ ┨ ┩ ┪ ┫ A9D0 ┬ ┭ ┮ ┯ ┰ ┱ ┲ ┳ ┴ ┵ ┶ ┷ ┸ ┹ ┺ ┻ A9E0 ┼ ┽ ┾ ┿ ╀ ╁ ╂ ╃ ╄ ╅ ╆ ╇ ╈ ╉ ╊ ╋ A9F0 第10区 code +0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +A +B +C +D +E +F AAA0 AAB0 AAC0 AAD0 AAE0 AAF0 第11区 code +0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +A +B +C +D +E +F ABA0 ABB0 ABC0 ABD0 ABE0 ABF0 第12区 code +0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +A +B +C +D +E +F ACA0 ACB0 ACC0 ACD0 ACE0 ACF0 第13区 code +0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +A +B +C +D +E +F ADA0 ADB0 ADC0 ADD0 ADE0 ADF0 第14区 code +0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +A +B +C +D +E +F AEA0 AEB0 AEC0 AED0 AEE0 AEF0 第15区 code +0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +A +B +C +D +E +F AFA0 AFB0 AFC0 AFD0 AFE0 AFF0 第16区 code +0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +A +B +C +D +E +F B0A0 啊 阿 埃 挨 哎 唉 哀 皑 癌 蔼 矮 艾 碍 爱 隘 B0B0 鞍 氨 安 俺 按 暗 岸 胺 案 肮 昂 盎 凹 敖 熬 翱 B0C0 袄 傲 奥 懊 澳 芭 捌 扒 叭 吧 笆 八 疤 巴 拔 跋 B0D0 靶 把 耙 坝 霸 罢 爸 白 柏 百 摆 佰 败 拜 稗 斑 B0E0 班 搬 扳 般 颁 板 版 扮 拌 伴 瓣 半 办 绊 邦 帮 B0F0 梆 榜 膀 绑 棒 磅 蚌 镑 傍 谤 苞 胞 包 褒 剥 第17区 code +0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +A +B +C +D +E +F B1A0 薄 雹 保 堡 饱 宝 抱 报 暴 豹 鲍 爆 杯 碑 悲 B1B0 卑 北 辈 背 贝 钡 倍 狈 备 惫 焙 被 奔 苯 本 笨 B1C0 崩 绷 甭 泵 蹦 迸 逼 鼻 比 鄙 笔 彼 碧 蓖 蔽 毕 B1D0 毙 毖 币 庇 痹 闭 敝 弊 必 辟 壁 臂 避 陛 鞭 边 B1E0 编 贬 扁 便 变 卞 辨 辩 辫 遍 标 彪 膘 表 鳖 憋 B1F0 别 瘪 彬 斌 濒 滨 宾 摈 兵 冰 柄 丙 秉 饼 炳 …… |
和Big5DistributionAnalysis:
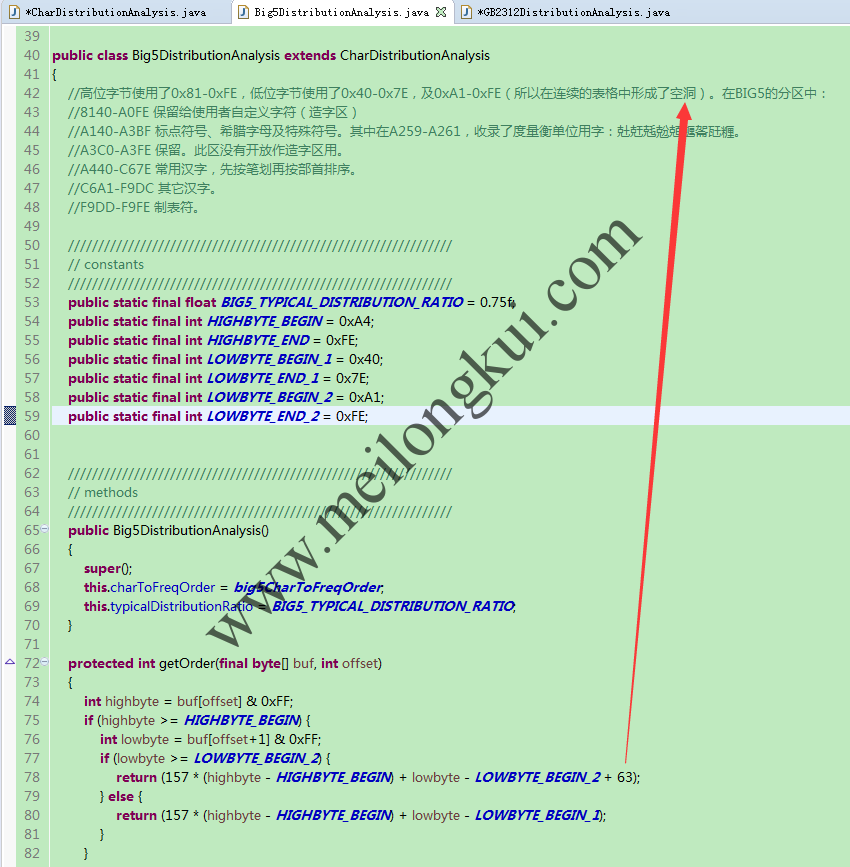
Big5DistributionAnalysis的原理
对于Big5而言,其中文字符开始于A440,这就是上图中getOrder的计算方法和‘空洞’的来源:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | |
| A140 | , | 、 | 。 | . | ‧ | ; | : | ? | ! | ︰ | … | ‥ | ﹐ | ﹑ | ﹒ | |
| A150 | · | ﹔ | ﹕ | ﹖ | ﹗ | | | – | ︱ | — | ︳ | ╴ | ︴ | ﹏ | ( | ) | ︵ |
| A160 | ︶ | { | } | ︷ | ︸ | 〔 | 〕 | ︹ | ︺ | 【 | 】 | ︻ | ︼ | 《 | 》 | ︽ |
| A170 | ︾ | 〈 | 〉 | ︿ | ﹀ | 「 | 」 | ﹁ | ﹂ | 『 | 』 | ﹃ | ﹄ | ﹙ | ﹚ | |
| A180 | ||||||||||||||||
| A190 | ||||||||||||||||
| A1A0 | ﹛ | ﹜ | ﹝ | ﹞ | ‘ | ’ | “ | ” | 〝 | 〞 | ‵ | ′ | # | & | * | |
| A1B0 | ※ | § | 〃 | ○ | ● | △ | ▲ | ◎ | ☆ | ★ | ◇ | ◆ | □ | ■ | ▽ | ▼ |
| A1C0 | ㊣ | ℅ | ¯ |  ̄ | _ | ˍ | ﹉ | ﹊ | ﹍ | ﹎ | ﹋ | ﹌ | ﹟ | ﹠ | ﹡ | + |
| A1D0 | - | × | ÷ | ± | √ | < | > | = | ≦ | ≧ | ≠ | ∞ | ≒ | ≡ | ﹢ | ﹣ |
| A1E0 | ﹤ | ﹥ | ﹦ | ~ | ∩ | ∪ | ⊥ | ∠ | ∟ | ⊿ | ㏒ | ㏑ | ∫ | ∮ | ∵ | ∴ |
| A1F0 | ♀ | ♂ | ⊕ | ⊙ | ↑ | ↓ | ← | → | ↖ | ↗ | ↙ | ↘ | ∥ | ∣ | / | |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | |
| A240 | \ | ∕ | ﹨ | $ | ¥ | 〒 | ¢ | £ | % | @ | ℃ | ℉ | ﹩ | ﹪ | ﹫ | ㏕ |
| A250 | ㎜ | ㎝ | ㎞ | ㏎ | ㎡ | ㎎ | ㎏ | ㏄ | ° | 兙 | 兛 | 兞 | 兝 | 兡 | 兣 | 嗧 |
| A260 | 瓩 | 糎 | ▁ | ▂ | ▃ | ▄ | ▅ | ▆ | ▇ | █ | ▏ | ▎ | ▍ | ▌ | ▋ | ▊ |
| A270 | ▉ | ┼ | ┴ | ┬ | ┤ | ├ | ▔ | ─ | │ | ▕ | ┌ | ┐ | └ | ┘ | ╭ | |
| A280 | ||||||||||||||||
| A290 | ||||||||||||||||
| A2A0 | ╮ | ╰ | ╯ | ═ | ╞ | ╪ | ╡ | ◢ | ◣ | ◥ | ◤ | ╱ | ╲ | ╳ | 0 | |
| A2B0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | Ⅰ | Ⅱ | Ⅲ | Ⅳ | Ⅴ | Ⅵ | Ⅶ |
| A2C0 | Ⅷ | Ⅸ | Ⅹ | 〡 | 〢 | 〣 | 〤 | 〥 | 〦 | 〧 | 〨 | 〩 | 十 | 卄 | 卅 | A |
| A2D0 | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q |
| A2E0 | R | S | T | U | V | W | X | Y | Z | a | b | c | d | e | f | g |
| A2F0 | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | |
| A340 | w | x | y | z | Α | Β | Γ | Δ | Ε | Ζ | Η | Θ | Ι | Κ | Λ | Μ |
| A350 | Ν | Ξ | Ο | Π | Ρ | Σ | Τ | Υ | Φ | Χ | Ψ | Ω | α | β | γ | δ |
| A360 | ε | ζ | η | θ | ι | κ | λ | μ | ν | ξ | ο | π | ρ | σ | τ | υ |
| A370 | φ | χ | ψ | ω | ㄅ | ㄆ | ㄇ | ㄈ | ㄉ | ㄊ | ㄋ | ㄌ | ㄍ | ㄎ | ㄏ | |
| A380 | ||||||||||||||||
| A390 | ||||||||||||||||
| A3A0 | ㄐ | ㄑ | ㄒ | ㄓ | ㄔ | ㄕ | ㄖ | ㄗ | ㄘ | ㄙ | ㄚ | ㄛ | ㄜ | ㄝ | ㄞ | |
| A3B0 | ㄟ | ㄠ | ㄡ | ㄢ | ㄣ | ㄤ | ㄥ | ㄦ | ㄧ | ㄨ | ㄩ | ˙ | ˉ | ˊ | ˇ | ˋ |
| A3C0 | ||||||||||||||||
| A3D0 | ||||||||||||||||
| A3E0 | ||||||||||||||||
| A3F0 | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | |
| A440 | 一 | 乙 | 丁 | 七 | 乃 | 九 | 了 | 二 | 人 | 儿 | 入 | 八 | 几 | 刀 | 刁 | 力 |
| A450 | 匕 | 十 | 卜 | 又 | 三 | 下 | 丈 | 上 | 丫 | 丸 | 凡 | 久 | 么 | 也 | 乞 | 于 |
| A460 | 亡 | 兀 | 刃 | 勺 | 千 | 叉 | 口 | 土 | 士 | 夕 | 大 | 女 | 子 | 孑 | 孓 | 寸 |
| A470 | 小 | 尢 | 尸 | 山 | 川 | 工 | 己 | 已 | 巳 | 巾 | 干 | 廾 | 弋 | 弓 | 才 | |
| A480 | ||||||||||||||||
| A490 | ||||||||||||||||
| A4A0 | 丑 | 丐 | 不 | 中 | 丰 | 丹 | 之 | 尹 | 予 | 云 | 井 | 互 | 五 | 亢 | 仁 | |
| A4B0 | 什 | 仃 | 仆 | 仇 | 仍 | 今 | 介 | 仄 | 元 | 允 | 內 | 六 | 兮 | 公 | 冗 | 凶 |
| A4C0 | 分 | 切 | 刈 | 勻 | 勾 | 勿 | 化 | 匹 | 午 | 升 | 卅 | 卞 | 厄 | 友 | 及 | 反 |
| A4D0 | 壬 | 天 | 夫 | 太 | 夭 | 孔 | 少 | 尤 | 尺 | 屯 | 巴 | 幻 | 廿 | 弔 | 引 | 心 |
| A4E0 | 戈 | 戶 | 手 | 扎 | 支 | 文 | 斗 | 斤 | 方 | 日 | 曰 | 月 | 木 | 欠 | 止 | 歹 |
| A4F0 | 毋 | 比 | 毛 | 氏 | 水 | 火 | 爪 | 父 | 爻 | 片 | 牙 | 牛 | 犬 | 王 | 丙 | |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | |
| A540 | 世 | 丕 | 且 | 丘 | 主 | 乍 | 乏 | 乎 | 以 | 付 | 仔 | 仕 | 他 | 仗 | 代 | 令 |
| A550 | 仙 | 仞 | 充 | 兄 | 冉 | 冊 | 冬 | 凹 | 出 | 凸 | 刊 | 加 | 功 | 包 | 匆 | 北 |
| A560 | 匝 | 仟 | 半 | 卉 | 卡 | 占 | 卯 | 卮 | 去 | 可 | 古 | 右 | 召 | 叮 | 叩 | 叨 |
| A570 | 叼 | 司 | 叵 | 叫 | 另 | 只 | 史 | 叱 | 台 | 句 | 叭 | 叻 | 四 | 囚 | 外 | |
| A580 | ||||||||||||||||
| A590 | ||||||||||||||||
| A5A0 | 央 | 失 | 奴 | 奶 | 孕 | 它 | 尼 | 巨 | 巧 | 左 | 市 | 布 | 平 | 幼 | 弁 | |
| A5B0 | 弘 | 弗 | 必 | 戊 | 打 | 扔 | 扒 | 扑 | 斥 | 旦 | 朮 | 本 | 未 | 末 | 札 | 正 |
| A5C0 | 母 | 民 | 氐 | 永 | 汁 | 汀 | 氾 | 犯 | 玄 | 玉 | 瓜 | 瓦 | 甘 | 生 | 用 | 甩 |
| A5D0 | 田 | 由 | 甲 | 申 | 疋 | 白 | 皮 | 皿 | 目 | 矛 | 矢 | 石 | 示 | 禾 | 穴 | 立 |
| A5E0 | 丞 | 丟 | 乒 | 乓 | 乩 | 亙 | 交 | 亦 | 亥 | 仿 | 伉 | 伙 | 伊 | 伕 | 伍 | 伐 |
| A5F0 | 休 | 伏 | 仲 | 件 | 任 | 仰 | 仳 | 份 | 企 | 伋 | 光 | 兇 | 兆 | 先 | 全 | |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | |
| A640 | 共 | 再 | 冰 | 列 | 刑 | 划 | 刎 | 刖 | 劣 | 匈 | 匡 | 匠 | 印 | 危 | 吉 | 吏 |
| A650 | 同 | 吊 | 吐 | 吁 | 吋 | 各 | 向 | 名 | 合 | 吃 | 后 | 吆 | 吒 | 因 | 回 | 囝 |
| A660 | 圳 | 地 | 在 | 圭 | 圬 | 圯 | 圩 | 夙 | 多 | 夷 | 夸 | 妄 | 奸 | 妃 | 好 | 她 |
| A670 | 如 | 妁 | 字 | 存 | 宇 | 守 | 宅 | 安 | 寺 | 尖 | 屹 | 州 | 帆 | 并 | 年 | |
| A680 | ||||||||||||||||
| A690 | ||||||||||||||||
| A6A0 | 式 | 弛 | 忙 | 忖 | 戎 | 戌 | 戍 | 成 | 扣 | 扛 | 托 | 收 | 早 | 旨 | 旬 | |
| A6B0 | 旭 | 曲 | 曳 | 有 | 朽 | 朴 | 朱 | 朵 | 次 | 此 | 死 | 氖 | 汝 | 汗 | 汙 | 江 |
| A6C0 | 池 | 汐 | 汕 | 污 | 汛 | 汍 | 汎 | 灰 | 牟 | 牝 | 百 | 竹 | 米 | 糸 | 缶 | 羊 |
| A6D0 | 羽 | 老 | 考 | 而 | 耒 | 耳 | 聿 | 肉 | 肋 | 肌 | 臣 | 自 | 至 | 臼 | 舌 | 舛 |
| A6E0 | 舟 | 艮 | 色 | 艾 | 虫 | 血 | 行 | 衣 | 西 | 阡 | 串 | 亨 | 位 | 住 | 佇 | 佗 |
| A6F0 | 佞 | 伴 | 佛 | 何 | 估 | 佐 | 佑 | 伽 | 伺 | 伸 | 佃 | 佔 | 似 | 但 | 佣 | |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | |
| A740 | 作 | 你 | 伯 | 低 | 伶 | 余 | 佝 | 佈 | 佚 | 兌 | 克 | 免 | 兵 | 冶 | 冷 | 別 |
| A750 | 判 | 利 | 刪 | 刨 | 劫 | 助 | 努 | 劬 | 匣 | 即 | 卵 | 吝 | 吭 | 吞 | 吾 | 否 |
| A760 | 呎 | 吧 | 呆 | 呃 | 吳 | 呈 | 呂 | 君 | 吩 | 告 | 吹 | 吻 | 吸 | 吮 | 吵 | 吶 |
| A770 | 吠 | 吼 | 呀 | 吱 | 含 | 吟 | 听 | 囪 | 困 | 囤 | 囫 | 坊 | 坑 | 址 | 坍 | |
| A780 | ||||||||||||||||
| A790 | ||||||||||||||||
| A7A0 | 均 | 坎 | 圾 | 坐 | 坏 | 圻 | 壯 | 夾 | 妝 | 妒 | 妨 | 妞 | 妣 | 妙 | 妖 | |
| A7B0 | 妍 | 妤 | 妓 | 妊 | 妥 | 孝 | 孜 | 孚 | 孛 | 完 | 宋 | 宏 | 尬 | 局 | 屁 | 尿 |
| A7C0 | 尾 | 岐 | 岑 | 岔 | 岌 | 巫 | 希 | 序 | 庇 | 床 | 廷 | 弄 | 弟 | 彤 | 形 | 彷 |
| A7D0 | 役 | 忘 | 忌 | 志 | 忍 | 忱 | 快 | 忸 | 忪 | 戒 | 我 | 抄 | 抗 | 抖 | 技 | 扶 |
| A7E0 | 抉 | 扭 | 把 | 扼 | 找 | 批 | 扳 | 抒 | 扯 | 折 | 扮 | 投 | 抓 | 抑 | 抆 | 改 |
| A7F0 | 攻 | 攸 | 旱 | 更 | 束 | 李 | 杏 | 材 | 村 | 杜 | 杖 | 杞 | 杉 | 杆 | 杠 | |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | |
| A840 | 杓 | 杗 | 步 | 每 | 求 | 汞 | 沙 | 沁 | 沈 | 沉 | 沅 | 沛 | 汪 | 決 | 沐 | 汰 |
| A850 | 沌 | 汨 | 沖 | 沒 | 汽 | 沃 | 汲 | 汾 | 汴 | 沆 | 汶 | 沍 | 沔 | 沘 | 沂 | 灶 |
| A860 | 灼 | 災 | 灸 | 牢 | 牡 | 牠 | 狄 | 狂 | 玖 | 甬 | 甫 | 男 | 甸 | 皂 | 盯 | 矣 |
| A870 | 私 | 秀 | 禿 | 究 | 系 | 罕 | 肖 | 肓 | 肝 | 肘 | 肛 | 肚 | 育 | 良 | 芒 | |
| A880 | ||||||||||||||||
| A890 | ||||||||||||||||
| A8A0 | 芋 | 芍 | 見 | 角 | 言 | 谷 | 豆 | 豕 | 貝 | 赤 | 走 | 足 | 身 | 車 | 辛 | |
| A8B0 | 辰 | 迂 | 迆 | 迅 | 迄 | 巡 | 邑 | 邢 | 邪 | 邦 | 那 | 酉 | 釆 | 里 | 防 | 阮 |
| A8C0 | 阱 | 阪 | 阬 | 並 | 乖 | 乳 | 事 | 些 | 亞 | 享 | 京 | 佯 | 依 | 侍 | 佳 | 使 |
| A8D0 | 佬 | 供 | 例 | 來 | 侃 | 佰 | 併 | 侈 | 佩 | 佻 | 侖 | 佾 | 侏 | 侑 | 佺 | 兔 |
| A8E0 | 兒 | 兕 | 兩 | 具 | 其 | 典 | 冽 | 函 | 刻 | 券 | 刷 | 刺 | 到 | 刮 | 制 | 剁 |
| A8F0 | 劾 | 劻 | 卒 | 協 | 卓 | 卑 | 卦 | 卷 | 卸 | 卹 | 取 | 叔 | 受 | 味 | 呵 | |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | |
| A940 | 咖 | 呸 | 咕 | 咀 | 呻 | 呷 | 咄 | 咒 | 咆 | 呼 | 咐 | 呱 | 呶 | 和 | 咚 | 呢 |
| A950 | 周 | 咋 | 命 | 咎 | 固 | 垃 | 坷 | 坪 | 坩 | 坡 | 坦 | 坤 | 坼 | 夜 | 奉 | 奇 |
| A960 | 奈 | 奄 | 奔 | 妾 | 妻 | 委 | 妹 | 妮 | 姑 | 姆 | 姐 | 姍 | 始 | 姓 | 姊 | 妯 |
| A970 | 妳 | 姒 | 姅 | 孟 | 孤 | 季 | 宗 | 定 | 官 | 宜 | 宙 | 宛 | 尚 | 屈 | 居 | |
| A980 | ||||||||||||||||
| A990 | ||||||||||||||||
| A9A0 | 屆 | 岷 | 岡 | 岸 | 岩 | 岫 | 岱 | 岳 | 帘 | 帚 | 帖 | 帕 | 帛 | 帑 | 幸 | |
| A9B0 | 庚 | 店 | 府 | 底 | 庖 | 延 | 弦 | 弧 | 弩 | 往 | 征 | 彿 | 彼 | 忝 | 忠 | 忽 |
| A9C0 | 念 | 忿 | 怏 | 怔 | 怯 | 怵 | 怖 | 怪 | 怕 | 怡 | 性 | 怩 | 怫 | 怛 | 或 | 戕 |
| A9D0 | 房 | 戾 | 所 | 承 | 拉 | 拌 | 拄 | 抿 | 拂 | 抹 | 拒 | 招 | 披 | 拓 | 拔 | 拋 |
| A9E0 | 拈 | 抨 | 抽 | 押 | 拐 | 拙 | 拇 | 拍 | 抵 | 拚 | 抱 | 拘 | 拖 | 拗 | 拆 | 抬 |
| A9F0 | 拎 | 放 | 斧 | 於 | 旺 | 昔 | 易 | 昌 | 昆 | 昂 | 明 | 昀 | 昏 | 昕 | 昊 | |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | |
| AA40 | 昇 | 服 | 朋 | 杭 | 枋 | 枕 | 東 | 果 | 杳 | 杷 | 枇 | 枝 | 林 | 杯 | 杰 | 板 |
| AA50 | 枉 | 松 | 析 | 杵 | 枚 | 枓 | 杼 | 杪 | 杲 | 欣 | 武 | 歧 | 歿 | 氓 | 氛 | 泣 |
| AA60 | 注 | 泳 | 沱 | 泌 | 泥 | 河 | 沽 | 沾 | 沼 | 波 | 沫 | 法 | 泓 | 沸 | 泄 | 油 |
| AA70 | 況 | 沮 | 泗 | 泅 | 泱 | 沿 | 治 | 泡 | 泛 | 泊 | 沬 | 泯 | 泜 | 泖 | 泠 | |
| AA80 | ||||||||||||||||
| AA90 | ||||||||||||||||
| AAA0 | 炕 | 炎 | 炒 | 炊 | 炙 | 爬 | 爭 | 爸 | 版 | 牧 | 物 | 狀 | 狎 | 狙 | 狗 | |
| AAB0 | 狐 | 玩 | 玨 | 玟 | 玫 | 玥 | 甽 | 疝 | 疙 | 疚 | 的 | 盂 | 盲 | 直 | 知 | 矽 |
| AAC0 | 社 | 祀 | 祁 | 秉 | 秈 | 空 | 穹 | 竺 | 糾 | 罔 | 羌 | 羋 | 者 | 肺 | 肥 | 肢 |
| AAD0 | 肱 | 股 | 肫 | 肩 | 肴 | 肪 | 肯 | 臥 | 臾 | 舍 | 芳 | 芝 | 芙 | 芭 | 芽 | 芟 |
| AAE0 | 芹 | 花 | 芬 | 芥 | 芯 | 芸 | 芣 | 芰 | 芾 | 芷 | 虎 | 虱 | 初 | 表 | 軋 | 迎 |
| AAF0 | 返 | 近 | 邵 | 邸 | 邱 | 邶 | 采 | 金 | 長 | 門 | 阜 | 陀 | 阿 | 阻 | 附 | |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | |
| AB40 | 陂 | 隹 | 雨 | 青 | 非 | 亟 | 亭 | 亮 | 信 | 侵 | 侯 | 便 | 俠 | 俑 | 俏 | 保 |
| AB50 | 促 | 侶 | 俘 | 俟 | 俊 | 俗 | 侮 | 俐 | 俄 | 係 | 俚 | 俎 | 俞 | 侷 | 兗 | 冒 |
| AB60 | 冑 | 冠 | 剎 | 剃 | 削 | 前 | 剌 | 剋 | 則 | 勇 | 勉 | 勃 | 勁 | 匍 | 南 | 卻 |
| AB70 | 厚 | 叛 | 咬 | 哀 | 咨 | 哎 | 哉 | 咸 | 咦 | 咳 | 哇 | 哂 | 咽 | 咪 | 品 | |
| AB80 | ||||||||||||||||
| AB90 | ||||||||||||||||
| ABA0 | 哄 | 哈 | 咯 | 咫 | 咱 | 咻 | 咩 | 咧 | 咿 | 囿 | 垂 | 型 | 垠 | 垣 | 垢 | |
| ABB0 | 城 | 垮 | 垓 | 奕 | 契 | 奏 | 奎 | 奐 | 姜 | 姘 | 姿 | 姣 | 姨 | 娃 | 姥 | 姪 |
| ABC0 | 姚 | 姦 | 威 | 姻 | 孩 | 宣 | 宦 | 室 | 客 | 宥 | 封 | 屎 | 屏 | 屍 | 屋 | 峙 |
| ABD0 | 峒 | 巷 | 帝 | 帥 | 帟 | 幽 | 庠 | 度 | 建 | 弈 | 弭 | 彥 | 很 | 待 | 徊 | 律 |
| ABE0 | 徇 | 後 | 徉 | 怒 | 思 | 怠 | 急 | 怎 | 怨 | 恍 | 恰 | 恨 | 恢 | 恆 | 恃 | 恬 |
| ABF0 | 恫 | 恪 | 恤 | 扁 | 拜 | 挖 | 按 | 拼 | 拭 | 持 | 拮 | 拽 | 指 | 拱 | 拷 | |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | |
| AC40 | 拯 | 括 | 拾 | 拴 | 挑 | 挂 | 政 | 故 | 斫 | 施 | 既 | 春 | 昭 | 映 | 昧 | 是 |
| AC50 | 星 | 昨 | 昱 | 昤 | 曷 | 柿 | 染 | 柱 | 柔 | 某 | 柬 | 架 | 枯 | 柵 | 柩 | 柯 |
| AC60 | 柄 | 柑 | 枴 | 柚 | 查 | 枸 | 柏 | 柞 | 柳 | 枰 | 柙 | 柢 | 柝 | 柒 | 歪 | 殃 |
| AC70 | 殆 | 段 | 毒 | 毗 | 氟 | 泉 | 洋 | 洲 | 洪 | 流 | 津 | 洌 | 洱 | 洞 | 洗 | |
| AC80 | ||||||||||||||||
| AC90 | ||||||||||||||||
| ACA0 | 活 | 洽 | 派 | 洶 | 洛 | 泵 | 洹 | 洧 | 洸 | 洩 | 洮 | 洵 | 洎 | 洫 | 炫 | |
| ACB0 | 為 | 炳 | 炬 | 炯 | 炭 | 炸 | 炮 | 炤 | 爰 | 牲 | 牯 | 牴 | 狩 | 狠 | 狡 | 玷 |
| ACC0 | 珊 | 玻 | 玲 | 珍 | 珀 | 玳 | 甚 | 甭 | 畏 | 界 | 畎 | 畋 | 疫 | 疤 | 疥 | 疢 |
| ACD0 | 疣 | 癸 | 皆 | 皇 | 皈 | 盈 | 盆 | 盃 | 盅 | 省 | 盹 | 相 | 眉 | 看 | 盾 | 盼 |
| ACE0 | 眇 | 矜 | 砂 | 研 | 砌 | 砍 | 祆 | 祉 | 祈 | 祇 | 禹 | 禺 | 科 | 秒 | 秋 | 穿 |
| ACF0 | 突 | 竿 | 竽 | 籽 | 紂 | 紅 | 紀 | 紉 | 紇 | 約 | 紆 | 缸 | 美 | 羿 | 耄 | |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | |
| AD40 | 耐 | 耍 | 耑 | 耶 | 胖 | 胥 | 胚 | 胃 | 胄 | 背 | 胡 | 胛 | 胎 | 胞 | 胤 | 胝 |
| AD50 | 致 | 舢 | 苧 | 范 | 茅 | 苣 | 苛 | 苦 | 茄 | 若 | 茂 | 茉 | 苒 | 苗 | 英 | 茁 |
| AD60 | 苜 | 苔 | 苑 | 苞 | 苓 | 苟 | 苯 | 茆 | 虐 | 虹 | 虻 | 虺 | 衍 | 衫 | 要 | 觔 |
| AD70 | 計 | 訂 | 訃 | 貞 | 負 | 赴 | 赳 | 趴 | 軍 | 軌 | 述 | 迦 | 迢 | 迪 | 迥 | |
| AD80 | ||||||||||||||||
| AD90 | ||||||||||||||||
| ADA0 | 迭 | 迫 | 迤 | 迨 | 郊 | 郎 | 郁 | 郃 | 酋 | 酊 | 重 | 閂 | 限 | 陋 | 陌 | |
| ADB0 | 降 | 面 | 革 | 韋 | 韭 | 音 | 頁 | 風 | 飛 | 食 | 首 | 香 | 乘 | 亳 | 倌 | 倍 |
| ADC0 | 倣 | 俯 | 倦 | 倥 | 俸 | 倩 | 倖 | 倆 | 值 | 借 | 倚 | 倒 | 們 | 俺 | 倀 | 倔 |
| ADD0 | 倨 | 俱 | 倡 | 個 | 候 | 倘 | 俳 | 修 | 倭 | 倪 | 俾 | 倫 | 倉 | 兼 | 冤 | 冥 |
| ADE0 | 冢 | 凍 | 凌 | 准 | 凋 | 剖 | 剜 | 剔 | 剛 | 剝 | 匪 | 卿 | 原 | 厝 | 叟 | 哨 |
| ADF0 | 唐 | 唁 | 唷 | 哼 | 哥 | 哲 | 唆 | 哺 | 唔 | 哩 | 哭 | 員 | 唉 | 哮 | 哪 | |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | |
| AE40 | 哦 | 唧 | 唇 | 哽 | 唏 | 圃 | 圄 | 埂 | 埔 | 埋 | 埃 | 堉 | 夏 | 套 | 奘 | 奚 |
| AE50 | 娑 | 娘 | 娜 | 娟 | 娛 | 娓 | 姬 | 娠 | 娣 | 娩 | 娥 | 娌 | 娉 | 孫 | 屘 | 宰 |
| AE60 | 害 | 家 | 宴 | 宮 | 宵 | 容 | 宸 | 射 | 屑 | 展 | 屐 | 峭 | 峽 | 峻 | 峪 | 峨 |
| AE70 | 峰 | 島 | 崁 | 峴 | 差 | 席 | 師 | 庫 | 庭 | 座 | 弱 | 徒 | 徑 | 徐 | 恙 | |
| AE80 | ||||||||||||||||
| AE90 | ||||||||||||||||
| AEA0 | 恣 | 恥 | 恐 | 恕 | 恭 | 恩 | 息 | 悄 | 悟 | 悚 | 悍 | 悔 | 悌 | 悅 | 悖 | |
| AEB0 | 扇 | 拳 | 挈 | 拿 | 捎 | 挾 | 振 | 捕 | 捂 | 捆 | 捏 | 捉 | 挺 | 捐 | 挽 | 挪 |
| AEC0 | 挫 | 挨 | 捍 | 捌 | 效 | 敉 | 料 | 旁 | 旅 | 時 | 晉 | 晏 | 晃 | 晒 | 晌 | 晅 |
| AED0 | 晁 | 書 | 朔 | 朕 | 朗 | 校 | 核 | 案 | 框 | 桓 | 根 | 桂 | 桔 | 栩 | 梳 | 栗 |
| AEE0 | 桌 | 桑 | 栽 | 柴 | 桐 | 桀 | 格 | 桃 | 株 | 桅 | 栓 | 栘 | 桁 | 殊 | 殉 | 殷 |
| AEF0 | 氣 | 氧 | 氨 | 氦 | 氤 | 泰 | 浪 | 涕 | 消 | 涇 | 浦 | 浸 | 海 | 浙 | 涓 | |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | |
| AF40 | 浬 | 涉 | 浮 | 浚 | 浴 | 浩 | 涌 | 涊 | 浹 | 涅 | 浥 | 涔 | 烊 | 烘 | 烤 | 烙 |
| AF50 | 烈 | 烏 | 爹 | 特 | 狼 | 狹 | 狽 | 狸 | 狷 | 玆 | 班 | 琉 | 珮 | 珠 | 珪 | 珞 |
| AF60 | 畔 | 畝 | 畜 | 畚 | 留 | 疾 | 病 | 症 | 疲 | 疳 | 疽 | 疼 | 疹 | 痂 | 疸 | 皋 |
| AF70 | 皰 | 益 | 盍 | 盎 | 眩 | 真 | 眠 | 眨 | 矩 | 砰 | 砧 | 砸 | 砝 | 破 | 砷 | |
| AF80 | ||||||||||||||||
| AF90 | ||||||||||||||||
| AFA0 | 砥 | 砭 | 砠 | 砟 | 砲 | 祕 | 祐 | 祠 | 祟 | 祖 | 神 | 祝 | 祗 | 祚 | 秤 | |
| AFB0 | 秣 | 秧 | 租 | 秦 | 秩 | 秘 | 窄 | 窈 | 站 | 笆 | 笑 | 粉 | 紡 | 紗 | 紋 | 紊 |
| AFC0 | 素 | 索 | 純 | 紐 | 紕 | 級 | 紜 | 納 | 紙 | 紛 | 缺 | 罟 | 羔 | 翅 | 翁 | 耆 |
| AFD0 | 耘 | 耕 | 耙 | 耗 | 耽 | 耿 | 胱 | 脂 | 胰 | 脅 | 胭 | 胴 | 脆 | 胸 | 胳 | 脈 |
| AFE0 | 能 | 脊 | 胼 | 胯 | 臭 | 臬 | 舀 | 舐 | 航 | 舫 | 舨 | 般 | 芻 | 茫 | 荒 | 荔 |
| AFF0 | 荊 | 茸 | 荐 | 草 | 茵 | 茴 | 荏 | 茲 | 茹 | 茶 | 茗 | 荀 | 茱 | 茨 | 荃 |
显然,在原始代码中有两个常量阈值:
public static final int ENOUGH_DATA_THRESHOLD = 1024;
public static final int MINIMUM_DATA_THRESHOLD = 4;
我们应该注意到,尽管juniversalchardet支持GB18083编码,但判断同时支持繁简体的GB18083统计规律(Character Distribution)的却是使用的仅仅针对简体GB2312统计规律的org.mozilla.universalchardet.prober.distributionanalysis.GB2312DistributionAnalysis。因此,对于‘區’(繁体的‘区’)字而言,GB2312DistributionAnalysis的getOrder方法将直接返回-1(即不认为是有效的GB2312字符)。当输入文本为:
byte[] buf = new byte[] { -78, -35, -63, -15, -55, -25, -123, 94 };
时,通过调试可以证明:
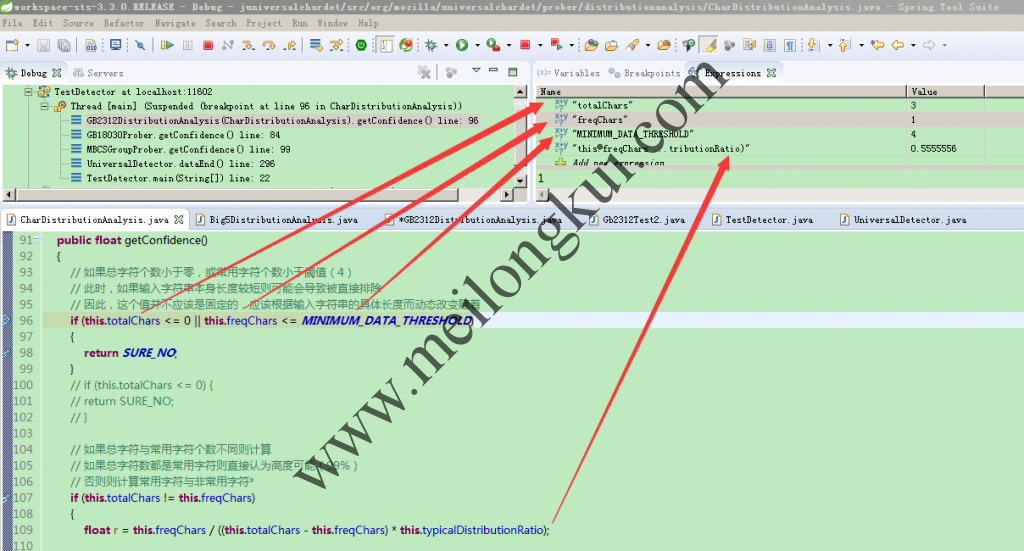
juniversalchardet调试1
此时,totalChars=3而不是4(因为‘區’不是有效的GB2312字符), 由于MINIMUM_DATA_THRESHOLD=4未被满足,因此上述输入文本被直接被认为SURE_NO(置信率=0.01),在后续的置信率的比较中也小于ISO-8895-7,导致了最终检测的不正确。
三、问题解决
由于Mozilla本身应对的场景是网页内容的编码检测,因此其可用的文本数量往往较多,这也是之所以ENOUGH_DATA_THRESHOLD被设置为1024的原因。不过,一旦输入本文较短,显然就存在误判的可能了。此时,有三种思路:
①优化GB2312DistributionAnalysis,增加针对GB18030编码的统计学规律(即org.mozilla.universalchardet.prober.distributionanalysis.GB18030DistributionAnalysis)。尽管GB18030的统计学规律没有直接数据,但可以结合BIG5DistributionAnalysis,既可以求出GB18030下的字符分布规律(需要进行BIG5到GB18030的映射,由于GB2312天然兼容,所以可以直接使用;由于GB18030码表较大,可能还需要考虑优化);
②根据输入文本的长度动态地决定MINIMUM_DATA_THRESHOLD;
③直接注释掉MINIMUM_DATA_THRESHOLD的判断,使用
float r = this.freqChars / ((this.totalChars – this.freqChars) * this.typicalDistributionRatio);
计算置信率。这是一种简单暴力的方法,但在相当程度上是可行的:
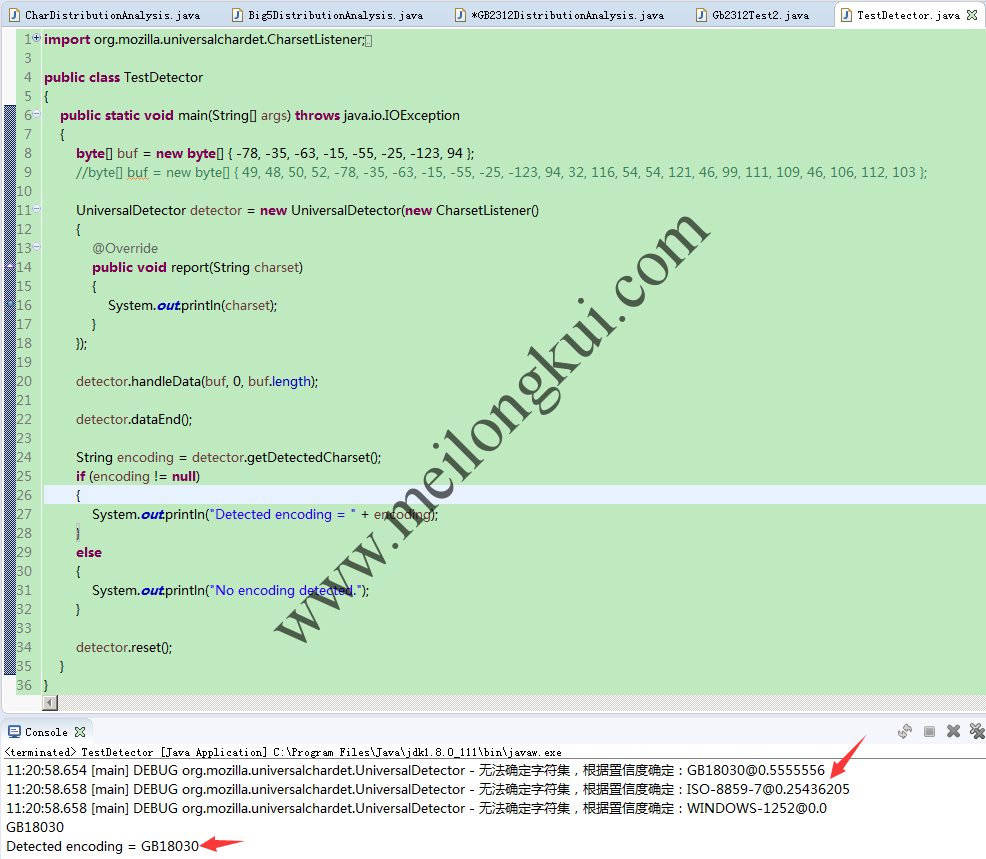
解决juniversalchardet在处理短文本时的BUG
转载时请保留出处,违法转载追究到底:进城务工人员小梅 » 解决juniversalchardet在处理短文本内容时结果错误的BUG
666,建议给那些库提一些PR呀