 进城务工人员小梅
进城务工人员小梅byte[] buf = new byte[] { -78, -35, -63, -15, -55, -25, -123, 94 };byte[] buf = new byte[] { 49, 48, 50, 52, -78, -35, -63, -15, -55, -25, -123, 94, 32, 116, 54, 54, 121, 46, 99, 111, 109, 46, 106, 112, 103 };
for (Map.Entry<String, Charset> ent : Charset.availableCharsets().entrySet())
{
System.out.print(ent.getKey());
CharBuffer charBuffer;
try
{
charBuffer = ent.getValue().newDecoder().decode(ByteBuffer.wrap(data));
}
catch (Exception e)
{
System.out.println(” failed when decoding.”);System.out.println();
continue;
}
System.out.print(” -> “);
System.out.append(charBuffer);System.out.println();
}
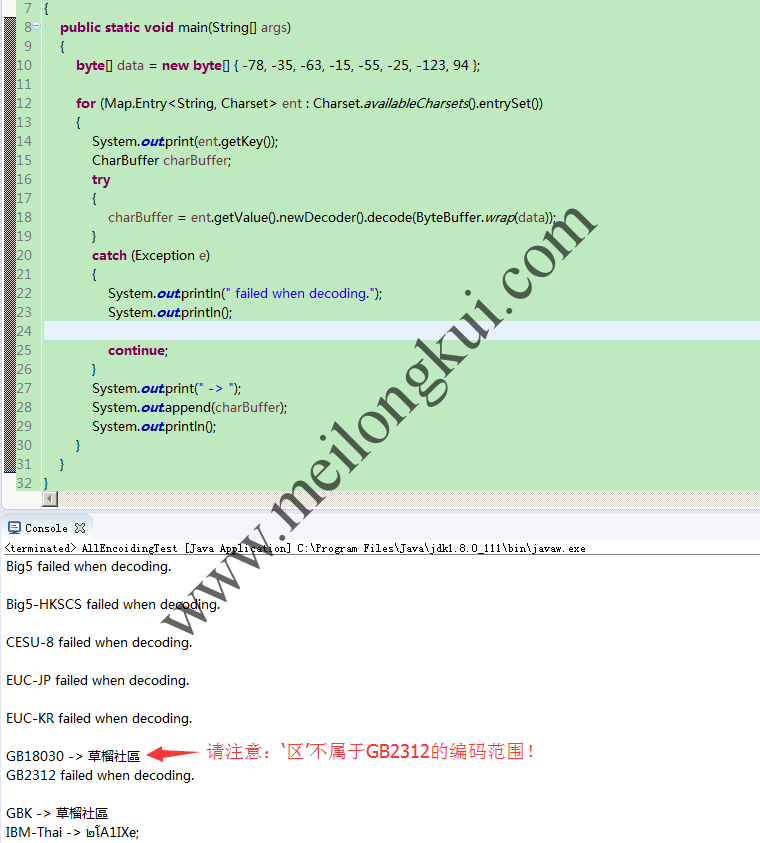
遍历所有可用编码来判断编码方式
①GB2312,中国国家标准简体中文字符集,全称《信息交换用汉字编码字符集·基本集》,由中国国家标准总局发布,1981年5月1日实施。GB2312标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;同时收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个字符,对任意一个图形字符都采用两个字节表示。GB2312基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。但对于繁体、人名、古汉语、少数民族文字等方面出现的罕用字,GB2312不能处理,导致了后来GBK及GB18030汉字字符集的出现。②GBK,Chinese Internal Code Specification,汉字内码扩展规范,K为汉语拼音Kuo Zhan(扩展)中“扩”字的声母。GBK共收录21886个汉字和图形符号,包括:GB2312中的全部汉字和非汉字符号、BIG5中的全部汉字、与 ISO10646相应的国家标准GB13000中的其它CJK汉字、其它汉字/部首/符号。GBK向下与GB2312完全兼容,向上支持ISO10646国际标准,在前者向后者过渡过程中起到的承上启下的作用。采用双字节表示。③GB18030,国家标准GB18030-2005《信息技术中文编码字符集》,是中华人民共和国现时最新的内码字集,是GB18030-2000《信息技术信息交换用汉字编码字符集基本集的扩充》的修订版。GB18030与GB2312-1980和GBK兼容,共收录汉字70244个。GB18030与UTF-8 相同,采用多字节编码,每个字可以由1个、2个或4个字节组成。编码空间庞大,最多可定义161万个字符。支持中国国内少数民族的文字,汉字收录范围包含繁体汉字以及日韩汉字。④BIG5,通行于台湾、香港地区的一个繁体中文编码方案。
https://www-archive.mozilla.org/projects/intl/chardet.htmlhttps://www-archive.mozilla.org/projects/intl/UniversalCharsetDetection.html
https://www.complang.tuwien.ac.at/doc/python-chardet/how-it-works.htmlhttps://github.com/PyYoshi/uchardet
https://github.com/thkoch2001/juniversalchardethttps://github.com/albfernandez/juniversalchardet
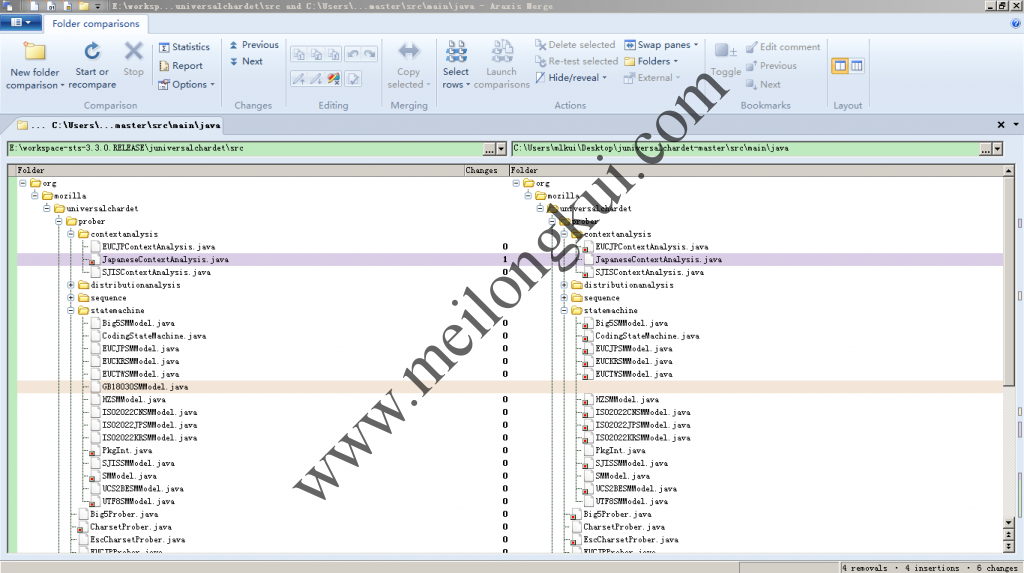
GitHub上两个juniversalchardet的对比
– Chinese
– ISO-2022-CN
– BIG-5
– EUC-TW
– GB18030
– HZ-GB-2312– Cyrillic
– ISO-8859-5
– KOI8-R
– WINDOWS-1251
– MACCYRILLIC
– IBM866
– IBM855– Greek
– ISO-8859-7
– WINDOWS-1253– Hebrew
– ISO-8859-8
– WINDOWS-1255– Japanese
– ISO-2022-JP
– Shift_JIS
– EUC-JP– Korean
– ISO-2022-KR
– EUC-KR– Unicode
– UTF-8
– UTF-16BE / UTF-16LE
– UTF-32BE / UTF-32LE / X-ISO-10646-UCS-4-3412 / X-ISO-10646-UCS-4-2143– Others
– WINDOWS-1252
import org.mozilla.universalchardet.CharsetListener;
import org.mozilla.universalchardet.UniversalDetector;public class TestDetector
{
public static void main(String[] args) throws java.io.IOException
{
// byte[] buf = new byte[] { -78, -35, -63, -15, -55, -25, -123, 94 };
byte[] buf = new byte[] { 49, 48, 50, 52, -78, -35, -63, -15, -55, -25, -123, 94, 32, 116, 54, 54, 121, 46, 99, 111, 109, 46, 106, 112, 103 };UniversalDetector detector = new UniversalDetector(new CharsetListener()
{
@Override
public void report(String charset)
{
System.out.println(charset);
}
});detector.handleData(buf, 0, buf.length);
detector.dataEnd();
String encoding = detector.getDetectedCharset();
if (encoding != null)
{
System.out.println(“Detected encoding = ” + encoding);
}
else
{
System.out.println(“No encoding detected.”);
}detector.reset();
}
}
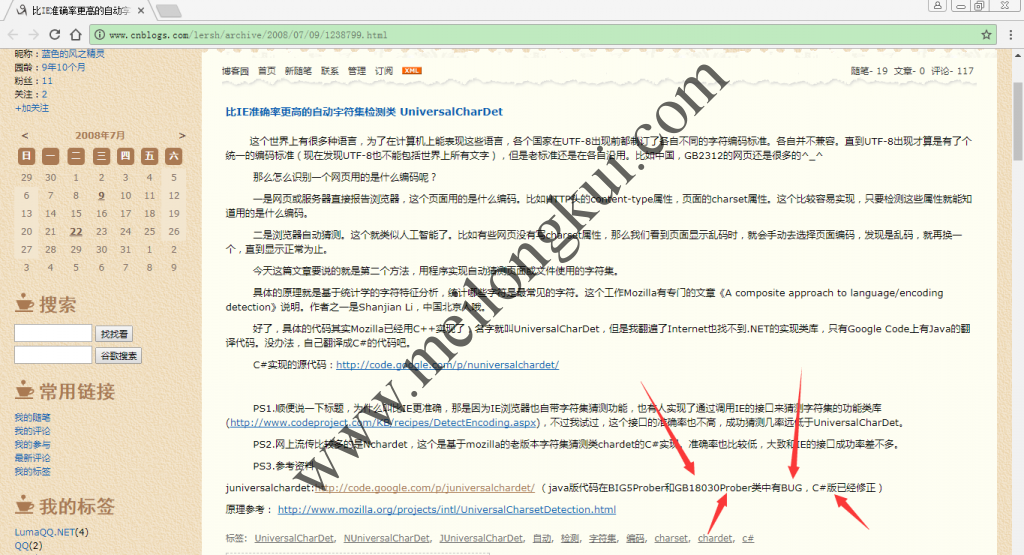
据称juniversalchardet存在BUG
https://github.com/thkoch2001/juniversalchardet/commit/3fd330c443272699cd8ba5d7da7e56c27a567ec1
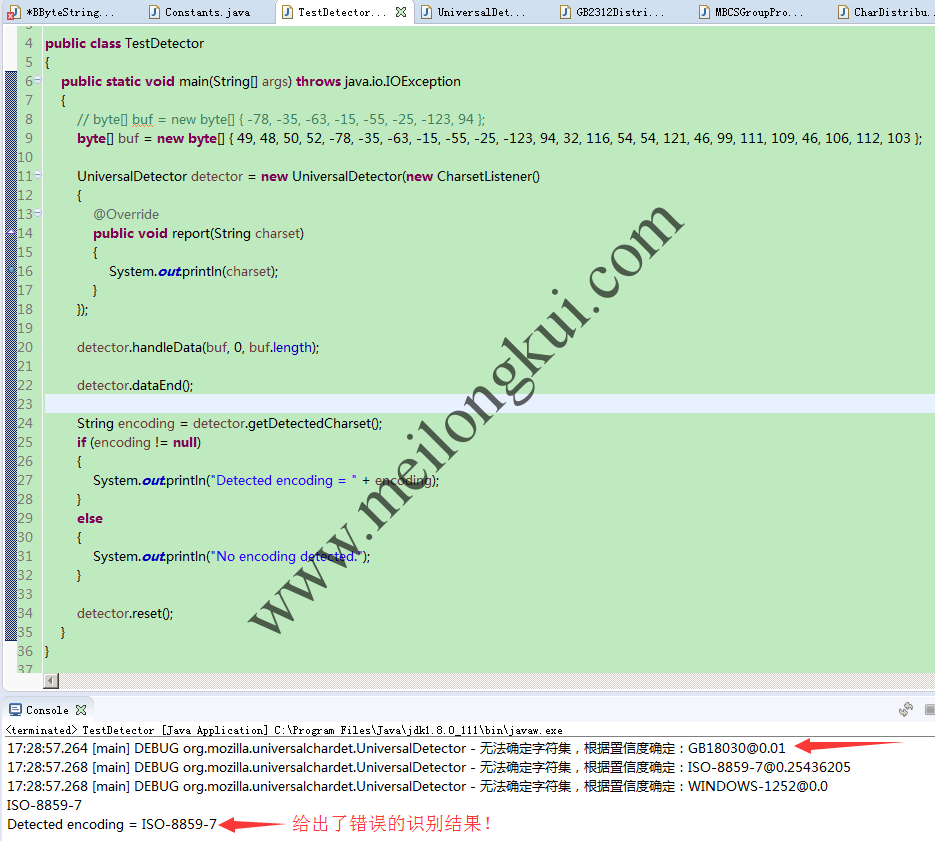
juniversalchardet识别中文编码错误
http://jchardet.sourceforge.net/
jchardet is another Java port of the Mozilla’s encoding dectection library. The main difference between jchardet and juniversalchardet is modules they are based on. jchardet is based on the “chardet” module that has long existed. juniversalchardet is based on the “universalchardet” module that is new and generally provides better accuracy on detection results.
package org.mozilla.intl.chardet.test;
import org.mozilla.intl.chardet.nsDetector;
import org.mozilla.intl.chardet.nsICharsetDetectionObserver;public class Test
{
public static void main(String[] args)
{
byte[] buf = new byte[] { 49, 48, 50, 52, -78, -35, -63, -15, -55, -25, -123, 94, 32, 116, 54, 54, 121, 46, 99, 111, 109, 46, 106, 112, 103 };nsDetector detector = new nsDetector();
detector.Init(new nsICharsetDetectionObserver()
{
public void Notify(String charset)
{
System.out.println(charset);
}
});Object done = detector.DoIt(buf, buf.length, false);
detector.DataEnd();
detector.Reset();
System.out.println(done);
}
}
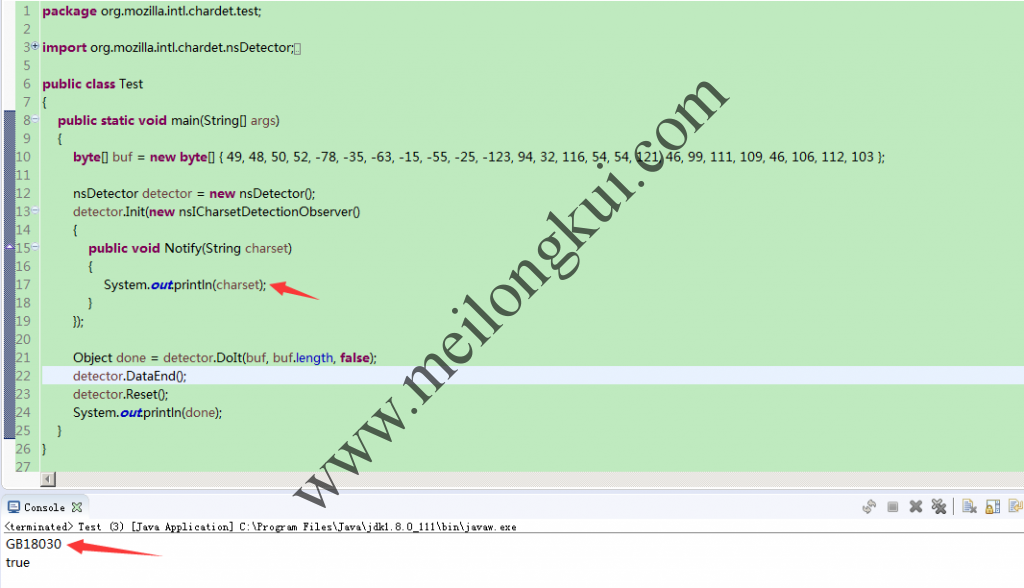
jchardet能够正确识别juniversalchardet识别错误的编码
https://github.com/thinksea/NChardet(作者是中国人)https://github.com/hollisterde/nuniversalchardet(http://code.google.com/p/nuniversalchardet,已废弃)
转载时请保留出处,违法转载追究到底:进城务工人员小梅 » 使用Java猜测或检测文本编码(Encoding detection),基于juniversalchardet和jchardet方案