 进城务工人员小梅
进城务工人员小梅在百度上搜索“语种识别”关键词时,有一个靠前的链接中提到使用Apache Tika进行语种识别:
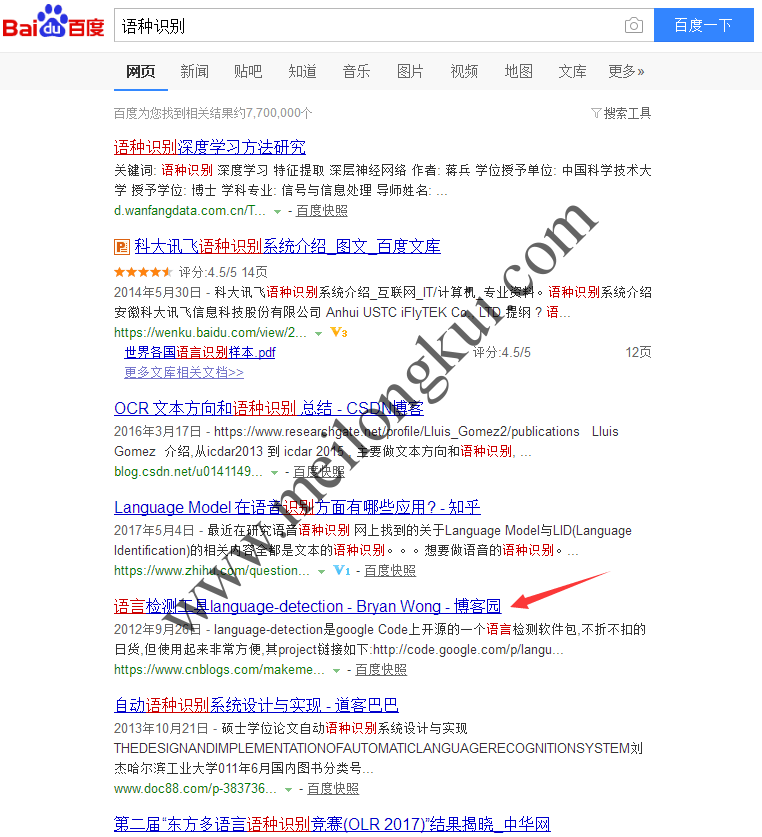
百度搜素“”语种检测“”的搜索结果
其中提到:
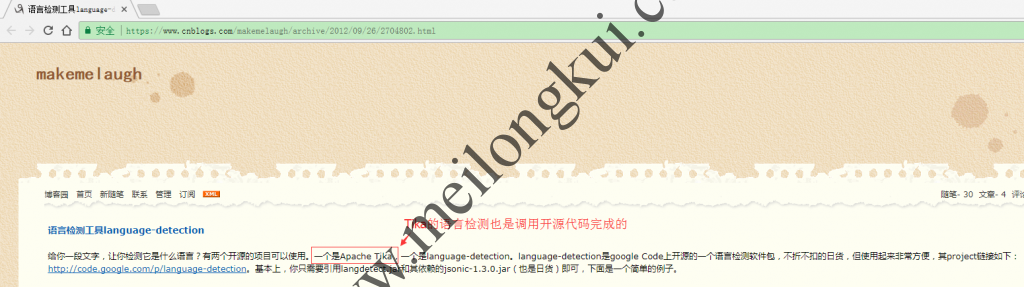
使用Apache Tika进行语种检测
但实际上,Tika做不了语言检测,Tika也是通过调用GitHub上的开源代码实现的。此前,Tika中是通过类org.apache.tika.language.LanguageIdentifier进行语种检测的;但目前,Tika中的类org.apache.tika.language.LanguageIdentifier已经被废弃,文档明确要求使用实现了org.apache.tika.language.detect.LanguageDetector接口的具体实现类:
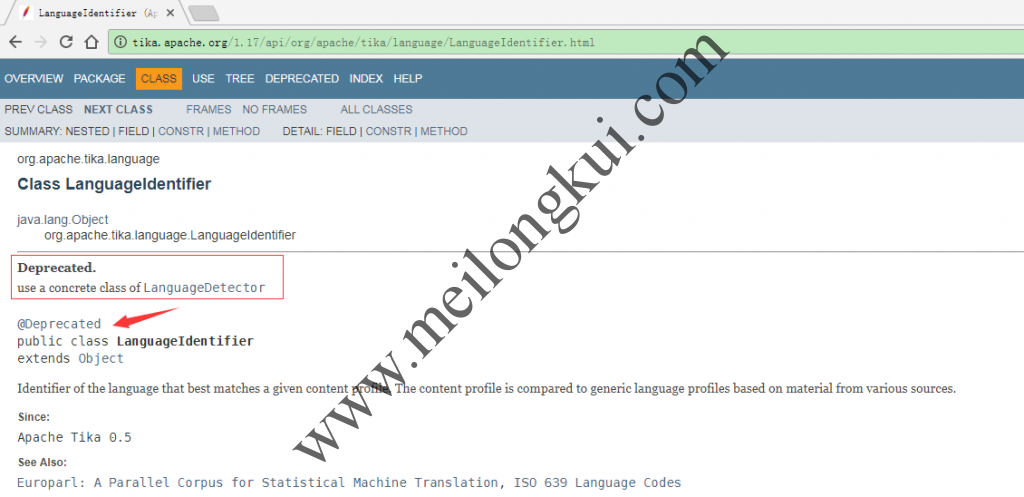
org.apache.tika.language.LanguageIdentifier已被废弃
在Tika中,有三个类实现了org.apache.tika.language.detect.LanguageDetector了接口:
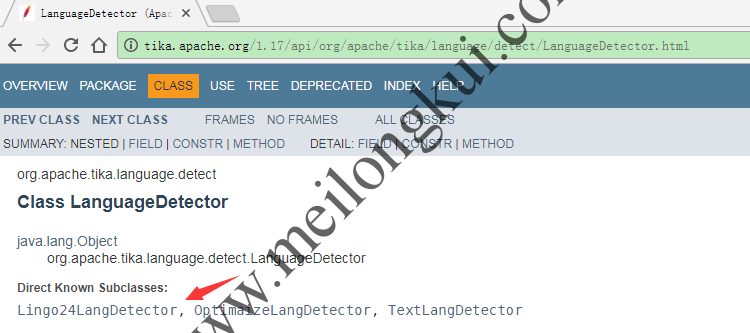
Tika中实现了org.apache.tika.language.detect.LanguageDetector接口的三个类
①org.apache.tika.langdetect.Lingo24LangDetector(An implementation of a Language Detector using the Premium MT API v1);
②org.apache.tika.langdetect.OptimaizeLangDetector(https://github.com/optimaize/language-detector);
③org.apache.tika.langdetect.TextLangDetector(https://github.com/trevorlewis/TextREST.jl);
其中只有org.apache.tika.langdetect.OptimaizeLangDetector是用本地方式进行的,即利用了com.optimaize.languagedetector(本站《使用Java进行语种识别(Language Detection),基于com.optimaize.languagedetector方案》一文中有详细说明),而其余两个均是对在线API的封装。
值得一提的是,org.apache.tika.langdetect.OptimaizeLangDetector中在构造com.optimaize.langdetect.LanguageDetector时调用了shortTextAlgorithm来处理短文本的问题:
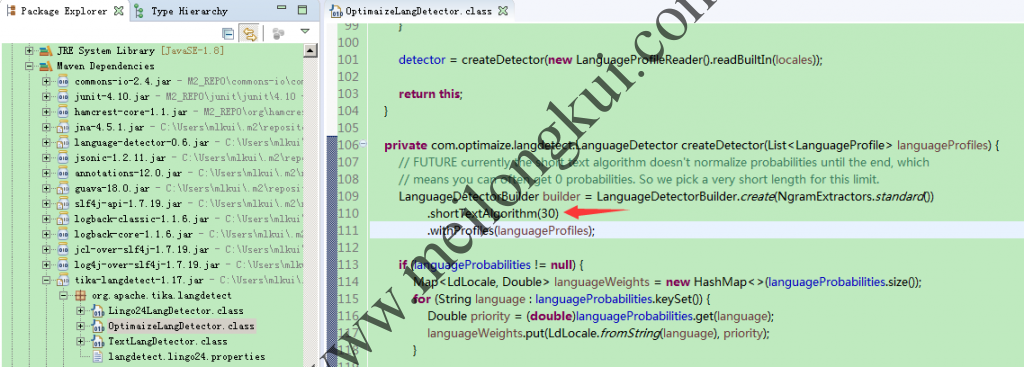
Tika调用了shortTextAlgorithm
转载时请保留出处,违法转载追究到底:进城务工人员小梅 » Apache Tika并不能直接用于语种识别