 进城务工人员小梅
进城务工人员小梅一、Parquet基础
Parquet是Apache的顶级项目,Parquet是一种面向分析的、平台/语言无关的、支持嵌套数据的列式存储格式,兼容Spark、Hive、Impala等,Parquet作为HDFS存储格式的事实标准之一(其他常用的列式存储格式还有RCFile和ORCFile等),经常用在离线数据仓库及OLAP等场景中。
关于行式存储与列式存储的区别可以简单用下图意会:
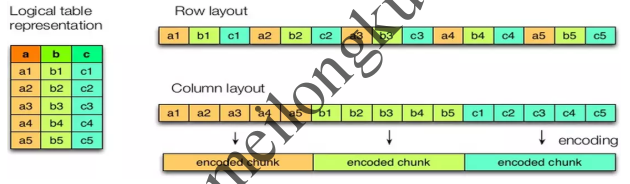
行式存储 vs 列式存储
列式存储格式下同一列的数据连续存放,因此在文件大小和查询性能上表现优秀:
1、因为同一列的数据类型相同且内容往往接近(例如时间戳、枚举值),所以可以针对不同列使用更合适的压缩与编码方式,从而降低所需的存储空间;
2、在很多情况只是希望读取文件中的若干列,因此可以通过投影模式、列裁剪、谓词下推等方式实现高效的列扫描,减少IO操作;
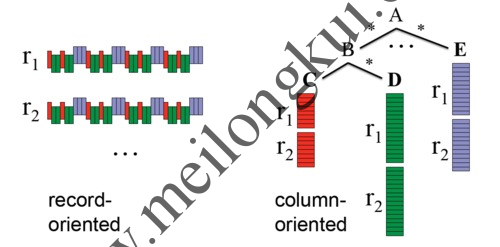
行式存储 vs 列式存储
Parquet的突出贡献在于能够以真正的列式存储格式来保存具有深度嵌套结构的数据,使用了Dremel编码,即模式中的每个原子类型的字段都单独存储为一列,且每个值通过两个整数对其结构进行编码,这两个整数分别是列定义深度(definition level)和列元素重复次数(repetition level),使得对任意一列(即使是嵌套列)数据的读取都不需要涉及到其他列。
Parquet只定义了很少的原子类型(连字符串都没有):
- BOOLEAN: 1 bit boolean
- INT32: 32 bit signed ints
- INT64: 64 bit signed ints
- INT96: 96 bit signed ints
- FLOAT: IEEE 32-bit floating point values
- DOUBLE: IEEE 64-bit floating point values
- BYTE_ARRAY: arbitrarily long byte arrays
保存在Parquet文件中的数据通过模式(Schema)描述,模式的根为message,message中包含多个字段,每一个字段又可以包含多个字段,每一个字段有三个属性组成:repetition、type和 name。其中,repetiton包括required(出现1次)、optional(出现0次或1次)、repeated(出现0次或多次);type分成两种:group(复杂类型)和 primitive(基本类型)。Parquet定义了一些逻辑类型(https://github.com/apache/parquet-format/blob/master/LogicalTypes.md),并通过逻辑注解来指出如何对原子类型进行解读,常见的包括:

Parquet常用逻辑类型
Parquet文件格式在逻辑上大致是:
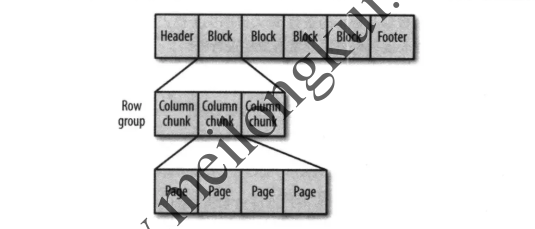
Parquet文件格式概念
对应官网上:
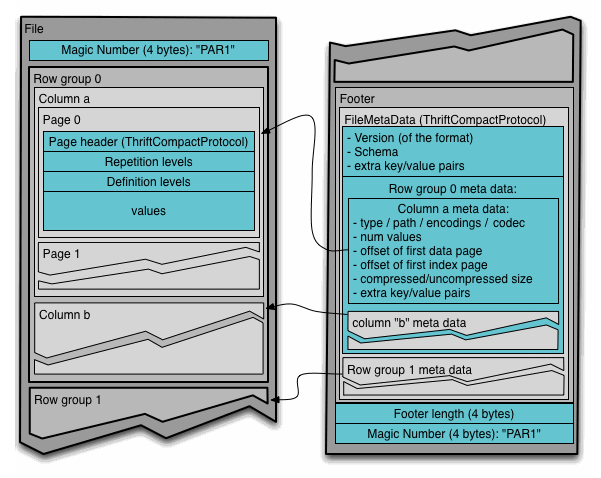
Parquet文件格式
一个Parquet文件包括:
1、文件(File):一个 Parquet文件,包括数据和元数据,如果在HDFS之上则分散存储在多个HDFS Block中;
2、行组(Row Group):数据在水平方向上按行拆分为多个单元,每个单元就是所谓的Row Group,即行组。每一个行组包含一定的行数,Parquet读写的时候会将整个行组缓存在内存中,因此更大尺寸的行组将会占用更多的缓存,记录占用空间比较小的Schema可以在每一个行组中存储更多的行;
3、列块(Column Chunk):一个行组中的每一列对应地保存在一个列块中。行组中的所有列连续的存储在这个行组文件中,每一个列块中的值都是相同类型的,不同列块可能使用不同的算法进行压缩;
3、数据页(Data Page):每一个列块划分为多个数据页或者说页,一个页是最小的编码的单位,在同一个列块的不同页可能使用不同的编码方式。
Parquet文件有三种类型的元数据,分别是file metadata、column(chunk) metadata、page header metadata:

Parquet元数据
应该注意到,Parquet文件最后同样包括了Magic字段,在读取Parquet文件时直接找到文件结尾然后减去八个字节即可定位文件块,故而Parquet文件是可分割且可并行处理的。
列式存储给数据压缩也提供了更大的发挥空间,除了常见的snappy、gzip等压缩方法以外,由于列式存储同一列的数据类型是一致的,所以可以使用更多的压缩算法:
|
压缩算法 |
使用场景 |
| Run Length Encoding | 重复数据 |
| Delta Encoding | 有序数据集,例如timestamp、自动生成的ID以及监控的各种metrics |
| Dictionary Encoding | 小规模的数据集合,例如IP地址 |
| Prefix Encoding | Delta Encoding for strings |
二、Hive针对HDFS中Parquet格式文件建表及查询
我们可以使用Apache的parquet-tools来对Parquet文件进行包括查看scheme等在内的操作。parquet-tools是parquet-mr的一部分(https://github.com/apache/parquet-mr/tree/master/parquet-tools),建议直接下载二进制:https://mvnrepository.com/artifact/org.apache.parquet/parquet-tools。parquet-tools分为local和hadoop环境下的两个版本,有如下的常用命令:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
[root@emr-header-1 ~]# hadoop jar parquet-tools-1.10.1.jar No command specified parquet-tools cat: Prints the content of a Parquet file. The output contains only the data, no metadata is displayed usage: parquet-tools cat [option...] <input> where option is one of: --debug Enable debug output -h,--help Show this help string -j,--json Show records in JSON format. --no-color Disable color output even if supported where <input> is the parquet file to print to stdout parquet-tools head: Prints the first n record of the Parquet file usage: parquet-tools head [option...] <input> where option is one of: --debug Enable debug output -h,--help Show this help string -n,--records <arg> The number of records to show (default: 5) --no-color Disable color output even if supported where <input> is the parquet file to print to stdout parquet-tools schema: Prints the schema of Parquet file(s) usage: parquet-tools schema [option...] <input> where option is one of: -d,--detailed Show detailed information about the schema. --debug Enable debug output -h,--help Show this help string --no-color Disable color output even if supported where <input> is the parquet file containing the schema to show parquet-tools meta: Prints the metadata of Parquet file(s) usage: parquet-tools meta [option...] <input> where option is one of: --debug Enable debug output -h,--help Show this help string --no-color Disable color output even if supported where <input> is the parquet file to print to stdout parquet-tools dump: Prints the content and metadata of a Parquet file usage: parquet-tools dump [option...] <input> where option is one of: -c,--column <arg> Dump only the given column, can be specified more than once -d,--disable-data Do not dump column data --debug Enable debug output -h,--help Show this help string -m,--disable-meta Do not dump row group and page metadata -n,--disable-crop Do not crop the output based on console width --no-color Disable color output even if supported where <input> is the parquet file to print to stdout parquet-tools merge: Merges multiple Parquet files into one. The command doesn't merge row groups, just places one after the other. When used to merge many small files, the resulting file will still contain small row groups, which usually leads to bad query performance. usage: parquet-tools merge [option...] <input> [<input> ...] <output> where option is one of: --debug Enable debug output -h,--help Show this help string --no-color Disable color output even if supported where <input> is the source parquet files/directory to be merged <output> is the destination parquet file parquet-tools rowcount: Prints the count of rows in Parquet file(s) usage: parquet-tools rowcount [option...] <input> where option is one of: -d,--detailed Detailed rowcount of each matching file --debug Enable debug output -h,--help Show this help string --no-color Disable color output even if supported where <input> is the parquet file to count rows to stdout parquet-tools size: Prints the size of Parquet file(s) usage: parquet-tools size [option...] <input> where option is one of: -d,--detailed Detailed size of each matching file --debug Enable debug output -h,--help Show this help string --no-color Disable color output even if supported -p,--pretty Pretty size -u,--uncompressed Uncompressed size where <input> is the parquet file to get size & human readable size to stdout [root@emr-header-1 ~]# |
例如,我们可以利用如下的命令:
|
1 |
hadoop jar parquet-tools-1.10.1.jar schema /path_to_the_file/filename.parquet |
查看某个Parquet文件的Schema:
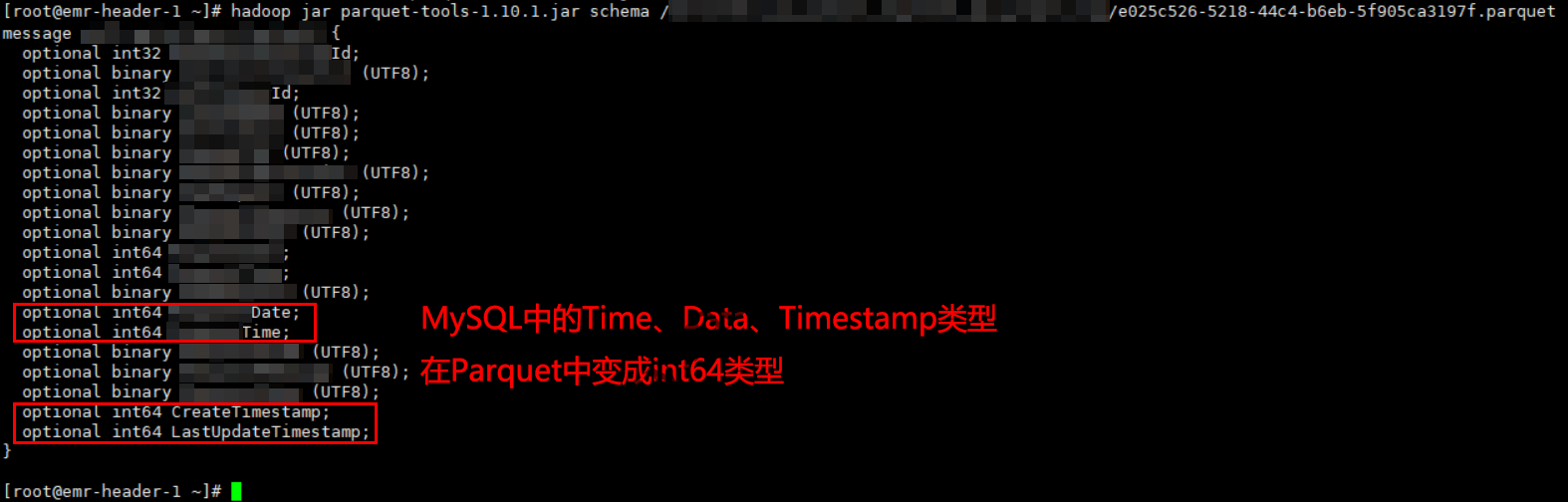
使用parquet-tools查看parquet文件的schema
我们还可以使用如下的命令:
|
1 |
hadoop jar parquet-tools-1.10.1.jar head /path_to_the_file/filename.parquet |
查看某个Parquet文件的前几行:
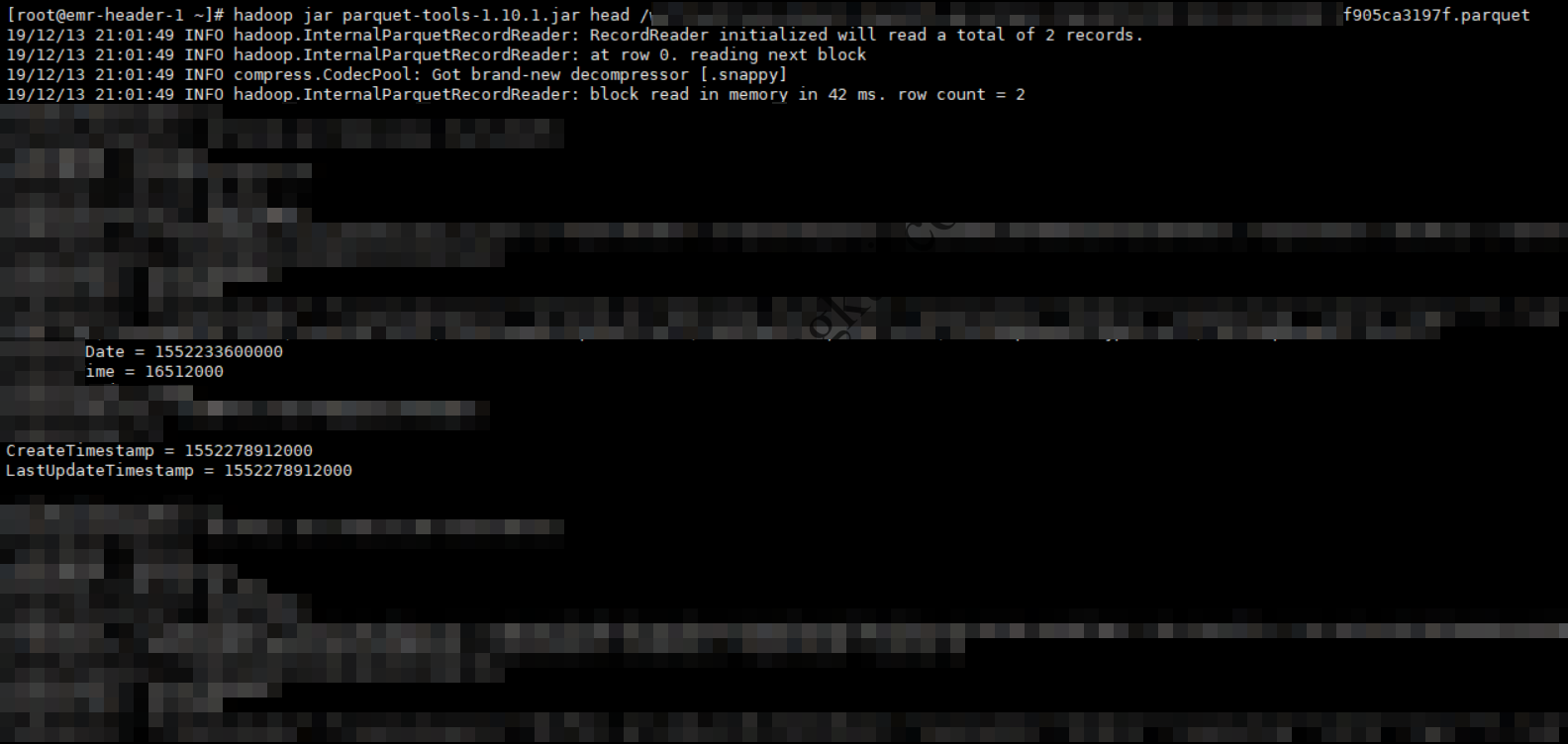
使用parquet-tools查看某个文件的前几行
值得注意的是:
0、Sqoop从MySQL导入时自动生成的Java类中能够正确处理MySQL数据中的Date、Time及Timestamp类型,能够被正确映射为java.sql.Date、java.sql.Time及java.sql.Timestamp;
1、Sqoop导MySQL到HDFS以Text文件格式存储时,MySQL时间类型Date、Time、Datetime、Timestamp会被转成Hive中的STRING类型,值为上述类型格式化后的字符串;
2、Sqoop导MySQL到HDFS以Parquet文件格式存储时,MySQL时间类型Date、Time、Datetime、Timestamp会被转成Hive中的BIGINT类型,值为毫秒时间戳。其中,time类型的看着比较奇怪,但实际也是毫秒时间戳,只是从1970-01-01开始的:
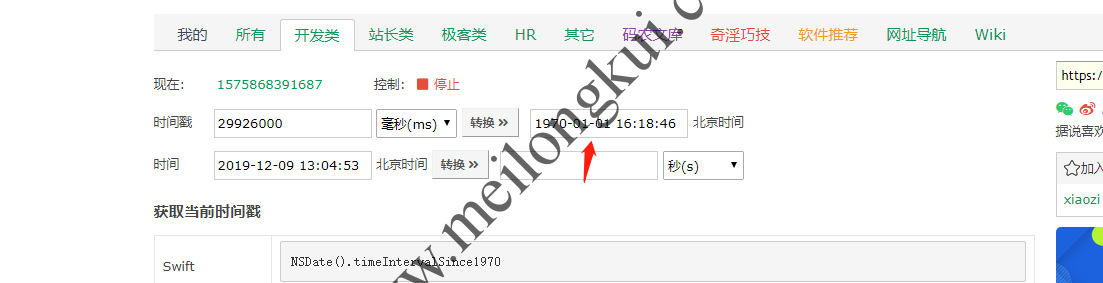
MySQL中Time类型的字段在Parquet文件中为从纪元开始的毫秒时间戳
其他的命令不赘述。
然后,我们根据在Hive中建表,首先使用beeline连接到HiveServer2:
使用Beeline连接到HiveServer2
使用HiveQL建立HDFS中Parquet文件所对应的Hive表,注意此处使用的是外部表而不是托管表(没有将表数据导入Hive的wearhouse):
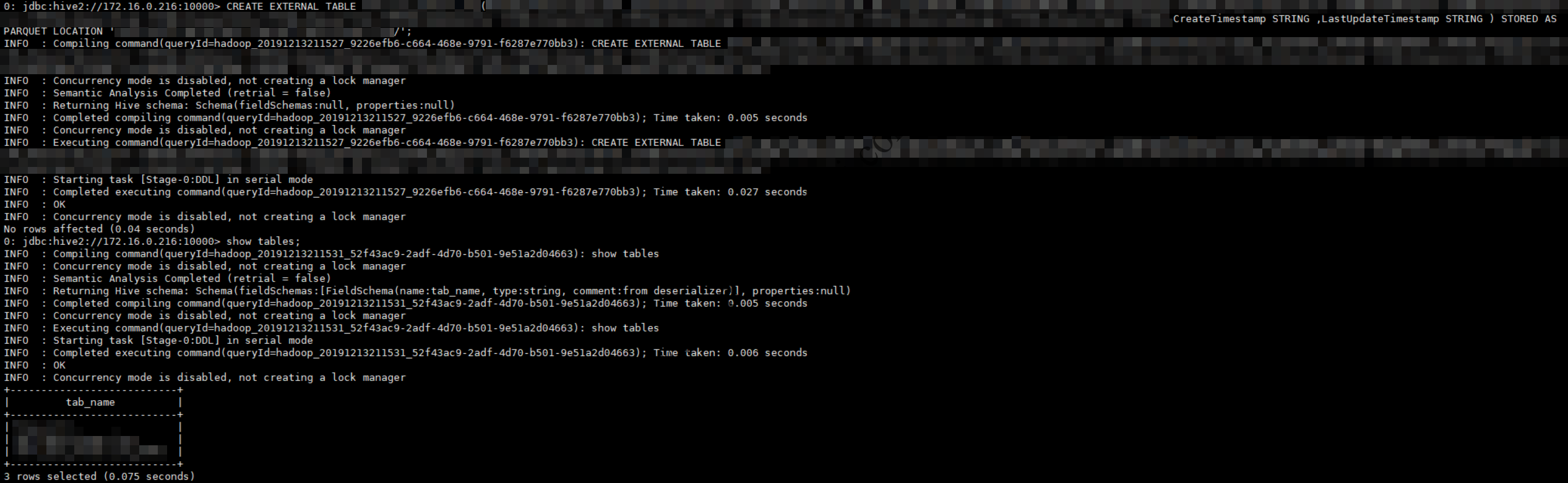
使用Hive基于Parquet文件创建外部表
然后加载表数据:

向外部表中加载数据
查看对应目录,会发现Hive没有将外部表对应的文件移动到默认的wirehouse目录下,而是重命名了一下:

Hive移动外部表对应的文件
在使用Hive时,我们经常会用到desc和desc formatted:
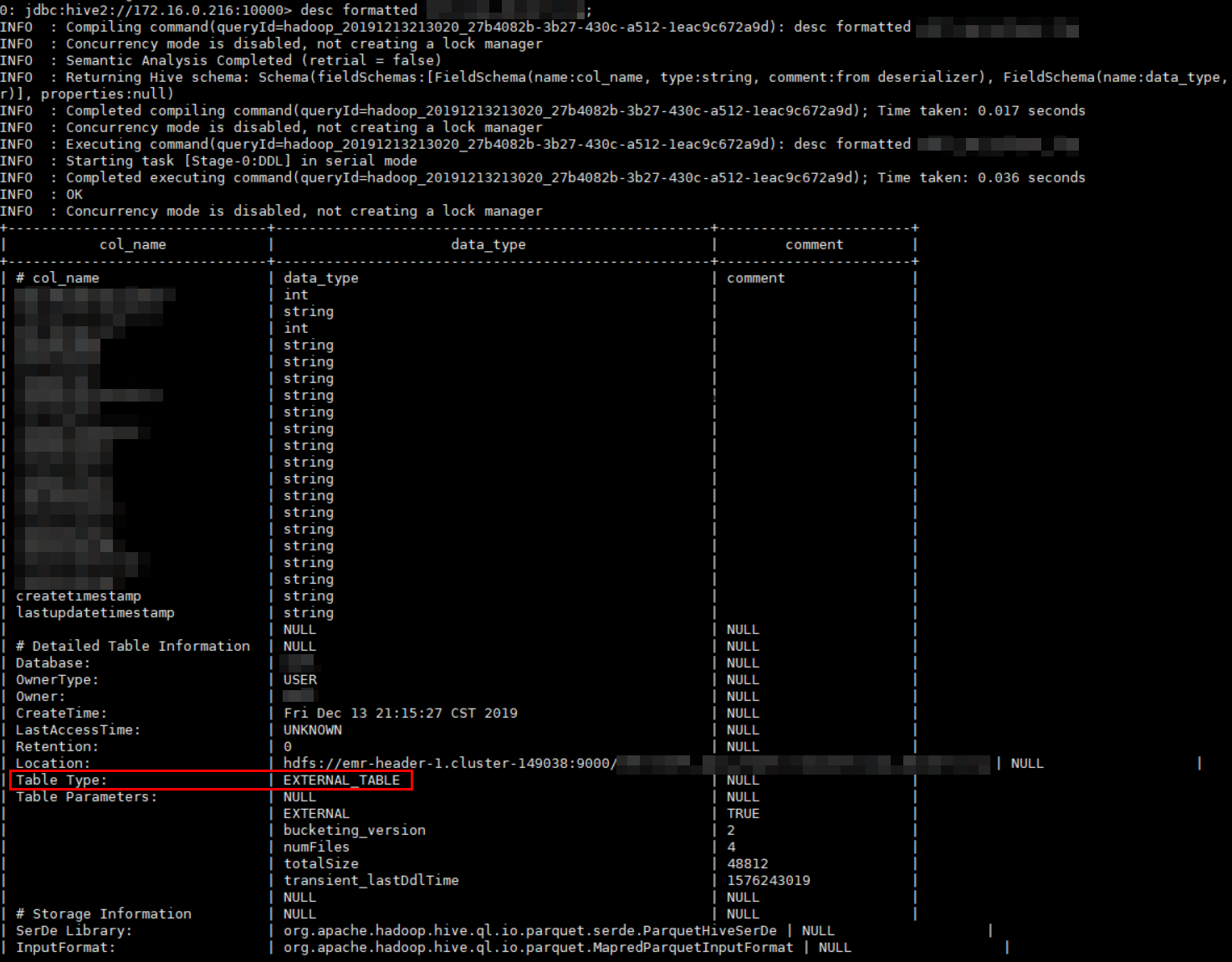
使用desc formateed查看表
在其中可以看到该表为外部表。
然后,我们正常使用HiveQL进行各种查询并耐心等待结果即可。
参考文档:
1、https://www.jianshu.com/p/8b32d05cc80b
2、https://blog.csdn.net/MuQianHuanHuoZhe/article/details/80514361
3、https://parquet.apache.org/documentation/latest
4、https://www.infoq.cn/article/in-depth-analysis-of-parquet-column-storage-format
5、https://www.cnblogs.com/wrencai/p/3935877.html,其中有–map-column-java、–map-column-hive的实例
6、http://sqoop.apache.org/docs/1.4.7/SqoopUserGuide.html#_importing_data_into_hive
7、https://stackoverflow.com/questions/33463869/converting-date-to-timestamp-in-hive,其中有数据库端做VIEW的实例;
转载时请保留出处,违法转载追究到底:进城务工人员小梅 » Hive针对HDFS中Parquet格式文件建表及查询