 进城务工人员小梅
进城务工人员小梅由于Hive采用了类似SQL的查询语言HiveQL,因此很容易将Hive理解为数据库。但其实上除了HiveQL是SQL的一种方言、Hive和数据库一样除了拥有类似的查询语言外,两者再无类似之处,Hive是为数据仓库而设计的,不适合用于联机事务处理,不支持事务,也不提供实时查询功能,适合基于大量不可变数据的批处理作业。HiveQL首先提交到Driver,然后调用Compiler, 最终解释成MapReduce任务执行(Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.),并将结果返回。
Hive的体系结构如下:
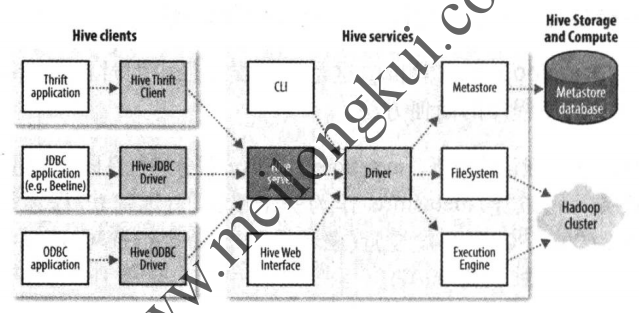
Hive架构
可以分为以下几部分:
1、用户接口主要有CLI、Client和HWI三种(Hive 2.2.0之后,HWI已经被从发行版中移除,https://issues.apache.org/jira/browse/HIVE-15622,源码中的hwi目录也已经被移除);
2、Hive将元数据存储在关系数据库中(metastore database),Hive中的元数据包括表的名字、表的列和分区及其属性、表的属性(是否为外部表等)、表的数据所在目录等;
3、解释器、编译器、优化器,完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成,生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行;
4、Hive中所有的数据都存储在HDFS中,存储结构主要包括数据库、文件、表和视图,大部分的查询、计算由MapReduce完成;
Hive将元数据存储在RDBMS中,metastore存储了Hive的元数据,包括两部分:metastore服务及metastore的后台数据。一般有Embedded metastore、Local metastore和Remote metastore三种:
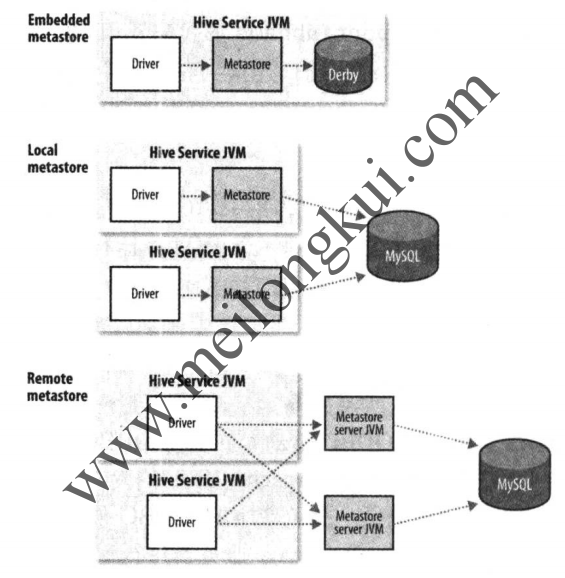
Hive metastore onfiguration
默认情况下为Embedded metastore方式,即metastore服务和Hive服务运行在同一个JVM中,并使用一个内嵌的、以本地磁盘作为存储的Derby数据库存储元数据,在这种方式下Hive表定义位于本地机器上,无法与其他用户共享,也不支持多会话。如果要支持多用户及多会会话,则需要使用一个独立的数据库,此时metastore和Hive service仍然运行在同一个JVM中,称为Local metastore方式。有关三种模式的具体细节可以参见《Hadoop权威指南 第四版》P478,我们选择使用Local metastore方式。
一、Hive基本配置
Hive只需在一个节点上部署即可,我们将其部署在master节点上。
从官网下载apache-hive-3.1.2-bin.tar.gz,然后使用
tar zvxf apache-hive-3.1.2-bin.tar.gz将其解压到apache-hive-3.1.2-bin。将HIVE_HOME加入到/etc/environment中:
|
1 2 3 4 5 |
JAVA_HOME="/usr/lib/java" CLASSPATH="/usr/lib/java/lib" HADOOP_HOME="/root/hadoop-3.2.1" HIVE_HOME="/root/apache-hive-3.1.2-bin" PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/usr/lib/java:/root/hadoop-3.2.1/bin" |
由于Hive使用了Hadoop(实际上正是从core-site.xml和yarn-site.xml中获取的有关HDFS和YARN的关键配置),因此HADOOP_HOME也需要在/etc/environment中,否则会报错:
|
1 |
Cannot find hadoop installation: $HADOOP_HOME or $HADOOP_PREFIX must be set or hadoop must be in the path |
之后,使用如下目录创建Hive在HDFS中的所需目录(hive.metastore.warehouse.dir对应的目录)并设置权限:
|
1 2 3 4 5 6 7 |
root@hadoop001:~/hadoop-3.2.1/bin# hadoop fs -mkdir /tmp root@hadoop001:~/hadoop-3.2.1/bin# hadoop fs -mkdir /user/hive root@hadoop001:~/hadoop-3.2.1/bin# hadoop fs -mkdir /user/hive/warehouse root@hadoop001:~/hadoop-3.2.1/bin# hadoop fs -chmod g+w /tmp root@hadoop001:~/hadoop-3.2.1/bin# hadoop fs -chmod g+w /user/hive root@hadoop001:~/hadoop-3.2.1/bin# hadoop fs -chmod g+w /user/hive/warehouse |
将conf目录下的hive-default.xml.template复制一份为hive-site.xml,这个配置文件很大,其中注明了这个文件是自动生成用于文档注释的:
|
1 2 3 |
<!-- WARNING!!! This file is auto generated for documentation purposes ONLY! --> <!-- WARNING!!! Any changes you make to this file will be ignored by Hive. --> <!-- WARNING!!! You must make your changes in hive-site.xml instead. --> |
将其中所有的配置项全部删掉,然后增加如下的配置项:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://rm-2zeq1c194u0tmp7n4.mysql.rds.aliyuncs.com:3306/hive?autoReconnect=true&autoReconnectForPools=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>hive@100FUTech101</value> </property> </configuration> |
二、初始化metastore数据库
按官网的说法:
Starting from Hive 2.1, we need to run the schematool command below as an initialization step.
我们使用MySQL数据库,建立schema即可,无需导入表,schema我们起名为hive。由于要操作MySQL数据库,因此我们需要将MySQL的JDBC Connector放到Hive的lib目录下:
|
1 2 3 4 |
root@iZ2ze1iqplyxdppzlsygn1Z:~/apache-hive-3.1.2-bin/lib# ls |grep mysql mysql-connector-java-5.1.47.jar mysql-metadata-storage-0.12.0.jar root@iZ2ze1iqplyxdppzlsygn1Z:~/apache-hive-3.1.2-bin/lib# |
运行hive/bin目录下 schematool -dbType mysql -initSchema初始化数据库:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
root@hadoop001:~/apache-hive-3.1.2-bin/bin# ./schematool -dbType mysql -initSchema SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/root/apache-hive-3.1.2-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/root/hadoop-3.2.1/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Metastore connection URL: jdbc:mysql://rm-2zeq1c194u0tmp7n4.mysql.rds.aliyuncs.com:3306/hive?autoReconnect=true&autoReconnectForPools=true Metastore Connection Driver : com.mysql.jdbc.Driver Metastore connection User: hive Wed Dec 04 22:53:53 CST 2019 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification. Starting metastore schema initialization to 3.1.0 Initialization script hive-schema-3.1.0.mysql.sql Wed Dec 04 22:53:54 CST 2019 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification. Initialization script completed Wed Dec 04 22:53:55 CST 2019 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification. schemaTool completed root@hadoop001:~/apache-hive-3.1.2-bin/bin# |
可以看到在MySQL中创建了Hive相关的表,多达七十多张:
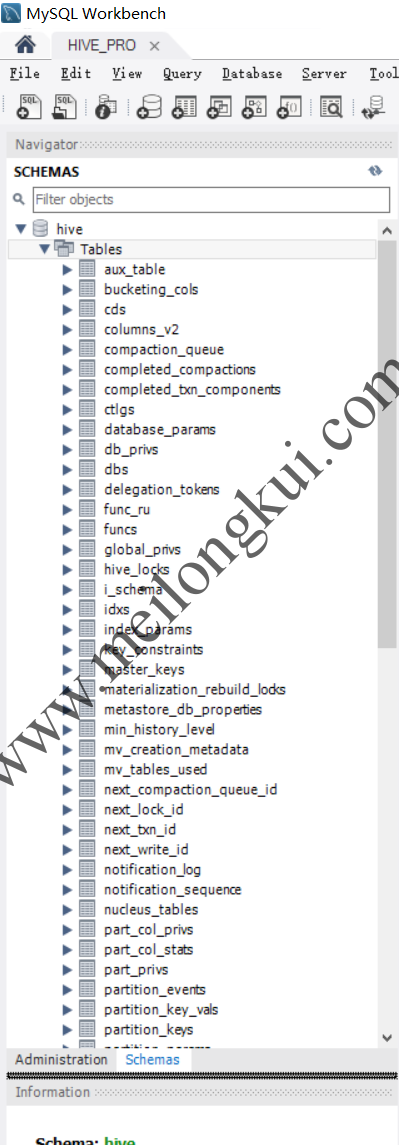
Hive的metadata表
三、Hive服务
Hive的Shell环境只是hive命令提供的其中一项服务,我们可以使用
hive --service help查看所有的service,默认的service其实就是cli:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
root@hadoop001:~/apache-hive-3.1.2-bin/bin# ./hive --service help Usage ./hive <parameters> --service serviceName <service parameters> Service List: beeline cleardanglingscratchdir cli fixacidkeyindex help hiveburninclient hiveserver2 hplsql jar lineage llapdump llap llapstatus metastore metatool orcfiledump rcfilecat schemaTool strictmanagedmigration tokentool version Parameters parsed: --auxpath : Auxiliary jars --config : Hive configuration directory --service : Starts specific service/component. cli is default Parameters used: HADOOP_HOME or HADOOP_PREFIX : Hadoop install directory HIVE_OPT : Hive options For help on a particular service: ./hive --service serviceName --help Debug help: ./hive --debug --help root@hadoop001:~/apache-hive-3.1.2-bin/bin# |
运行 ./hive实际上等价于 ./hive --service cli,对于Hive 3.1.2 on Hadoop 3.2.1而言会报错:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
root@hadoop1:~/apache-hive-3.1.2-bin/bin# export HADOOP_HOME="/root/hadoop-3.2.1" root@hadoop1:~/apache-hive-3.1.2-bin/bin# ./hive SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/root/apache-hive-3.1.2-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/root/hadoop-3.2.1/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V at org.apache.hadoop.conf.Configuration.set(Configuration.java:1357) at org.apache.hadoop.conf.Configuration.set(Configuration.java:1338) at org.apache.hadoop.mapred.JobConf.setJar(JobConf.java:536) at org.apache.hadoop.mapred.JobConf.setJarByClass(JobConf.java:554) at org.apache.hadoop.mapred.JobConf.<init>(JobConf.java:448) at org.apache.hadoop.hive.conf.HiveConf.initialize(HiveConf.java:5141) at org.apache.hadoop.hive.conf.HiveConf.<init>(HiveConf.java:5099) at org.apache.hadoop.hive.common.LogUtils.initHiveLog4jCommon(LogUtils.java:97) at org.apache.hadoop.hive.common.LogUtils.initHiveLog4j(LogUtils.java:81) at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:699) at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:683) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.util.RunJar.run(RunJar.java:323) at org.apache.hadoop.util.RunJar.main(RunJar.java:236) |
经查,是由于Hive发行版内依赖的Guava版本和Hadoop内依赖的Guava版本不一致造成的,解决方法是查看Hadoop目录下share/hadoop/common/lib和Hive目录下lib内的guava.jar版本是否一致,若不一致则删除版本低的并拷贝高版本的即可:
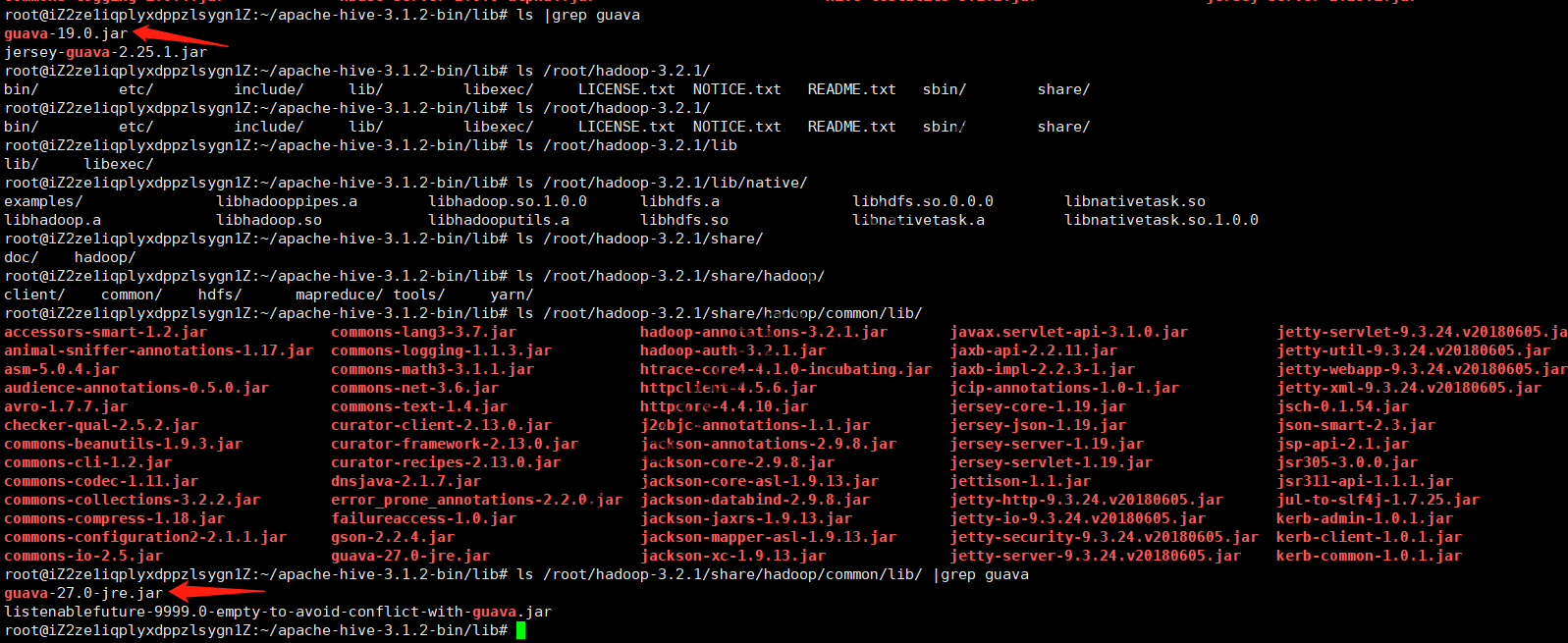
Hive和Hadoop使用了冲突的Guava
然后就可以在Hive Shell中进行操作了。
此外,Hive服务常用的还包括metastore,这主要用于Remote metastore的配置模式。
四、使用Hive CLI
我们在Hive Shell中进行一下测试:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
hive> show databases; OK default Time taken: 0.308 seconds, Fetched: 1 row(s) hive> show tables; OK Time taken: 0.077 seconds hive> create database hive_test; OK Time taken: 0.189 seconds hive> show databases; OK default hive_test Time taken: 0.034 seconds, Fetched: 2 row(s) hive> |
能够看到HDFS中对应的数据:
|
1 2 3 4 5 6 7 8 9 10 11 |
root@hadoop001:~/hadoop-3.2.1/bin# hadoop fs -ls /user/ Found 2 items drwxr-xr-x - root supergroup 0 2019-12-04 22:22 /user/hive drwxr-xr-x - root supergroup 0 2019-12-02 23:51 /user/input root@hadoop001:~/hadoop-3.2.1/bin# hadoop fs -ls /user/hive Found 1 items drwxr-xr-x - root supergroup 0 2019-12-04 23:18 /user/hive/warehouse root@hadoop001:~/hadoop-3.2.1/bin# hadoop fs -ls /user/hive/warehouse Found 1 items drwxr-xr-x - root supergroup 0 2019-12-04 23:18 /user/hive/warehouse/hive_test.db root@hadoop001:~/hadoop-3.2.1/bin# |
五、使用HiveServer2服务
根据官网文档,直接使用
./hiveserver2命令即可启动HiveServer2,此时即所谓以服务器的方式运行Hive:
|
1 |
hiveserver2 |
hiveserver2实际是个脚本文件,实际就是 hive --service hiveserver2,这样就可以在应用程序中使用不同的Thrift客户端或JDBC客户端连接到Hive了,hiveserver2的Thrift默认端口为10000和10001:
|
1 2 3 4 5 6 7 8 9 10 |
<property> <name>hive.server2.thrift.port</name> <value>10000</value> <description>Port number of HiveServer2 Thrift interface when hive.server2.transport.mode is 'binary'.</description> </property> <property> <name>hive.server2.thrift.http.port</name> <value>10001</value> <description>Port number of HiveServer2 Thrift interface when hive.server2.transport.mode is 'http'.</description> </property> |
此时,HiveServer2是在前台运行的,如果要后台运行需要使用nohup。
五、Web UI
Hive目前已经移除了HWI,此处指的Web UI是HiveServer2的Web UI,默认端口是10002:
|
1 2 3 4 5 6 7 8 9 10 |
<property> <name>hive.server2.webui.host</name> <value>0.0.0.0</value> <description>The host address the HiveServer2 WebUI will listen on</description> </property> <property> <name>hive.server2.webui.port</name> <value>10002</value> <description>The port the HiveServer2 WebUI will listen on. This can beset to 0 or a negative integer to disable the web UI</description> </property> |
hiveserver2 WebUI
六、Beeline及其他客户端
根据官网的说法,Hive CLI已被弃用,与hiveserver2配合的是Beeline:
HiveServer2 (introduced in Hive 0.11) has its own CLI called Beeline. HiveCLI is now deprecated in favor of Beeline, as it lacks the multi-user, security, and other capabilities of HiveServer2.
Beeline启动时需要HiveServer2的JDBC URL作为参数,默认连接时使用的是Thrift的10000端口:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 |
root@hadoop001:~/apache-hive-3.1.2-bin/bin# ./beeline --help SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/root/apache-hive-3.1.2-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/root/hadoop-3.2.1/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Usage: java org.apache.hive.cli.beeline.BeeLine -u <database url> the JDBC URL to connect to -c <named url> the named JDBC URL to connect to, which should be present in beeline-site.xml as the value of beeline.hs2.jdbc.url.<namedUrl> -r reconnect to last saved connect url (in conjunction with !save) -n <username> the username to connect as -p <password> the password to connect as -d <driver class> the driver class to use -i <init file> script file for initialization -e <query> query that should be executed -f <exec file> script file that should be executed -w (or) --password-file <password file> the password file to read password from --hiveconf property=value Use value for given property --hivevar name=value hive variable name and value This is Hive specific settings in which variables can be set at session level and referenced in Hive commands or queries. --property-file=<property-file> the file to read connection properties (url, driver, user, password) from --color=[true/false] control whether color is used for display --showHeader=[true/false] show column names in query results --escapeCRLF=[true/false] show carriage return and line feeds in query results as escaped \r and \n --headerInterval=ROWS; the interval between which heades are displayed --fastConnect=[true/false] skip building table/column list for tab-completion --autoCommit=[true/false] enable/disable automatic transaction commit --verbose=[true/false] show verbose error messages and debug info --showWarnings=[true/false] display connection warnings --showDbInPrompt=[true/false] display the current database name in the prompt --showNestedErrs=[true/false] display nested errors --numberFormat=[pattern] format numbers using DecimalFormat pattern --force=[true/false] continue running script even after errors --maxWidth=MAXWIDTH the maximum width of the terminal --maxColumnWidth=MAXCOLWIDTH the maximum width to use when displaying columns --silent=[true/false] be more silent --autosave=[true/false] automatically save preferences --outputformat=[table/vertical/csv2/tsv2/dsv/csv/tsv] format mode for result display Note that csv, and tsv are deprecated - use csv2, tsv2 instead --incremental=[true/false] Defaults to false. When set to false, the entire result set is fetched and buffered before being displayed, yielding optimal display column sizing. When set to true, result rows are displayed immediately as they are fetched, yielding lower latency and memory usage at the price of extra display column padding. Setting --incremental=true is recommended if you encounter an OutOfMemory on the client side (due to the fetched result set size being large). Only applicable if --outputformat=table. --incrementalBufferRows=NUMROWS the number of rows to buffer when printing rows on stdout, defaults to 1000; only applicable if --incremental=true and --outputformat=table --truncateTable=[true/false] truncate table column when it exceeds length --delimiterForDSV=DELIMITER specify the delimiter for delimiter-separated values output format (default: |) --isolation=LEVEL set the transaction isolation level --nullemptystring=[true/false] set to true to get historic behavior of printing null as empty string --maxHistoryRows=MAXHISTORYROWS The maximum number of rows to store beeline history. --delimiter=DELIMITER set the query delimiter; multi-char delimiters are allowed, but quotation marks, slashes, and -- are not allowed; defaults to ; --convertBinaryArrayToString=[true/false] display binary column data as string or as byte array --help display this message Example: 1. Connect using simple authentication to HiveServer2 on localhost:10000 $ beeline -u jdbc:hive2://localhost:10000 username password 2. Connect using simple authentication to HiveServer2 on hs.local:10000 using -n for username and -p for password $ beeline -n username -p password -u jdbc:hive2://hs2.local:10012 3. Connect using Kerberos authentication with hive/localhost@mydomain.com as HiveServer2 principal $ beeline -u "jdbc:hive2://hs2.local:10013/default;principal=hive/localhost@mydomain.com" 4. Connect using SSL connection to HiveServer2 on localhost at 10000 $ beeline "jdbc:hive2://localhost:10000/default;ssl=true;sslTrustStore=/usr/local/truststore;trustStorePassword=mytruststorepassword" 5. Connect using LDAP authentication $ beeline -u jdbc:hive2://hs2.local:10013/default <ldap-username> <ldap-password> |
我们可以使用 ./beeline -u jdbc:hive2://localhost:10000连接到HiveServer2,但如果是以root用户运行的话会报错“root is not allowed to impersonate anonymous”,因此一般hive也必然是使用非root的其他用户运行的:
|
1 2 3 4 5 6 7 8 9 10 11 |
root@hadoop001:~/apache-hive-3.1.2-bin/bin# ./beeline -u jdbc:hive2://localhost:10000 SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/root/apache-hive-3.1.2-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/root/hadoop-3.2.1/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Connecting to jdbc:hive2://localhost:10000 19/12/05 17:22:37 [main]: WARN jdbc.HiveConnection: Failed to connect to localhost:10000 Error: Could not open client transport with JDBC Uri: jdbc:hive2://localhost:10000: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: root is not allowed to impersonate anonymous (state=08S01,code=0) Beeline version 3.1.2 by Apache Hive root@hadoop001:~/apache-hive-3.1.2-bin/bin# ye至此,Hive的部署基本完成,有关Hive JDBC用户验证的问题将在单独的文章中说明。 |
也可以在beeline的shell中使用!connect进行连接:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
[root@emr-header-1 ~]# beeline log4j:ERROR Could not find value for key log4j.appender. log4j:ERROR Could not instantiate appender named "". Beeline version 2.3.5 by Apache Hive beeline> !connect Usage: connect <url> <username> <password> [driver] beeline> !connect jdbc:hive2://172.16.0.216:10000 Connecting to jdbc:hive2://172.16.0.216:10000 Enter username for jdbc:hive2://172.16.0.216:10000: username Enter password for jdbc:hive2://172.16.0.216:10000: ************ log4j:WARN No appenders could be found for logger (org.apache.hive.jdbc.Utils). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info. Connected to: Apache Hive (version 3.1.1) Driver: Hive JDBC (version 2.3.5) Transaction isolation: TRANSACTION_REPEATABLE_READ 0: jdbc:hive2://172.16.0.216:10000> show tables; INFO : Compiling command(queryId=hadoop_20191209112649_6bd4506f-0d6c-4ce8-8e47-4324ef4e08a6): show tables INFO : Concurrency mode is disabled, not creating a lock manager INFO : Semantic Analysis Completed (retrial = false) INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:tab_name, type:string, comment:from deserializer)], properties:null) INFO : Completed compiling command(queryId=hadoop_20191209112649_6bd4506f-0d6c-4ce8-8e47-4324ef4e08a6); Time taken: 0.442 seconds INFO : Concurrency mode is disabled, not creating a lock manager INFO : Executing command(queryId=hadoop_20191209112649_6bd4506f-0d6c-4ce8-8e47-4324ef4e08a6): show tables INFO : Starting task [Stage-0:DDL] in serial mode INFO : Completed executing command(queryId=hadoop_20191209112649_6bd4506f-0d6c-4ce8-8e47-4324ef4e08a6); Time taken: 0.033 seconds INFO : OK INFO : Concurrency mode is disabled, not creating a lock manager +-----------+ | tab_name | +-----------+ +-----------+ No rows selected (0.655 seconds) 0: jdbc:hive2://172.16.0.216:10000> |
参考文档:
1、https://cwiki.apache.org/confluence/display/Hive/GettingStarted#GettingStarted-InstallationandConfiguration
2、https://www.cnblogs.com/zimo-jing/p/9028949.html
3、https://blog.csdn.net/GQB1226/article/details/102555820
4、《Hadoop 权威指南 第四版》P476
5、https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients
6、https://blog.csdn.net/xxw_sample/article/details/80244938
7、https://cwiki.apache.org/confluence/display/Hive/Setting+up+HiveServer2#SettingUpHiveServer2-Authentication/SecurityConfiguration
转载时请保留出处,违法转载追究到底:进城务工人员小梅 » Hive 3.1.2 on Hadoop 3.2.1(Local Metastore with MySQL)部署