 进城务工人员小梅
进城务工人员小梅从官网上下载Hadoop,当前最新版是3.1.2:

从官网下载Hadoop
使用 tar zvxf hadoop-3.1.2.tar.gz解压,并在所有机器上使用 sudo vim /etc/environment修改环境变量:

将Hadoop加入到PATH中
主要修改点包括增加HADOOP_HOME和在PATH中增加Hadoop的bin目录:
|
1 2 |
HADOOP_HOME="/root/hadoop-3.1.2" PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/usr/lib/java:/root/hadoop-3.1.2/bin" |
修改/etc/hosts文件,将主机名和ip地址的映射填写进去:
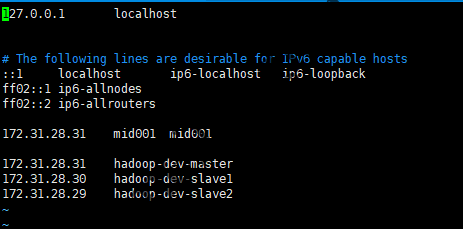
增加hostname映射
一、建立SSH免密互访
Hadoop控制脚本依赖SSH来执行针对整个集群的操作,因此需要允许集群内部间各机器的SSH免密互访。首先在所有节点上执行生成SSH密钥对:
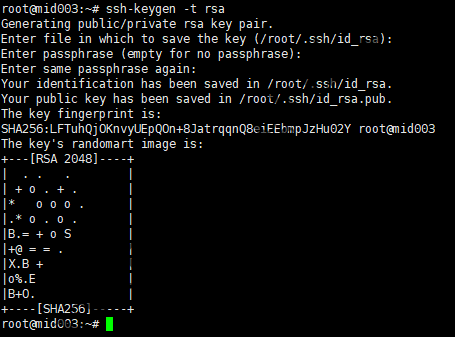
生成SSH密钥对
然后将各自的公钥拷贝到集群中其他机器的authorized_keys文件中,可用下面的笨方法:
①在master上将其自己的公钥放到authorized_keys里;
②在master上使用scp命令将authorized_keys放到其他主机的.ssh目录下;
③如有必要,修改authorized_keys权限,chmod 644 authorized_keys;
④依次在各台机器上重复上述过程;

添加SSH公钥
我们也可以直接使用ssh-copy-id,ssh-copy-id命令会把本地主机的公钥复制到远程主机的authorized_keys文件中,同时给远程主机的用户主目录(home)和~/.ssh和~/.ssh/authorized_keys设置合适的权限:
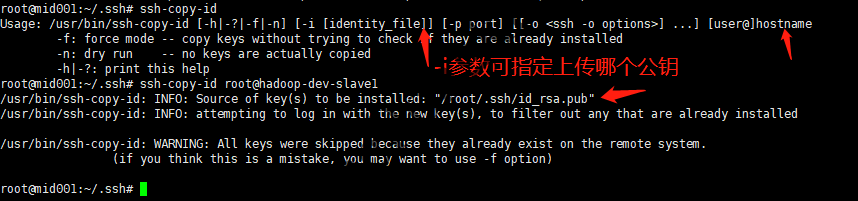
使用ssh-copy-id将本地SSH公钥增加至远程服务器的authorized_keys文件中
总之,让每台机器的authorized_keys中均包含其他机器的公钥即可(authorized_keys文件是有格式的,能够方便地看出包含了哪些机器的公钥),然后就可以直接通过形如 ssh hadoop-dev-slave1之类的命令在master、slave1、slave2之间实现免密访问了:

authorized_keys
二、HDFS的基础搭建
由于HDFS是一切的基础,因此我们首先来搭建HDFS。首先是namenode的配置文件:
|
1 2 3 4 5 6 7 8 9 10 |
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop-dev-master:18020</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:///root/hadoop-dev/tmp</value> </property> </configuration> |
core-site.xml中fs.defaultFS默认端口为8020,datanode也需要该配置文件。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///root/hadoop-dev/dfs/name</value> </property> <property> <name>dfs.namenode.checkpoint.dir</name> <value>file:///root/hadoop-dev/dfs/checkpoint</value> </property> </configuration> |
然后是两个datanode的配置文件:
|
1 2 3 4 5 6 7 8 9 10 |
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop-dev-master:18020</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:///root/hadoop-dev/tmp</value> </property> </configuration> |
和
|
1 2 3 4 5 6 7 8 9 10 |
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///root/hadoop-dev/dfs/data</value> </property> </configuration> |
之后,格式化namenode系统:
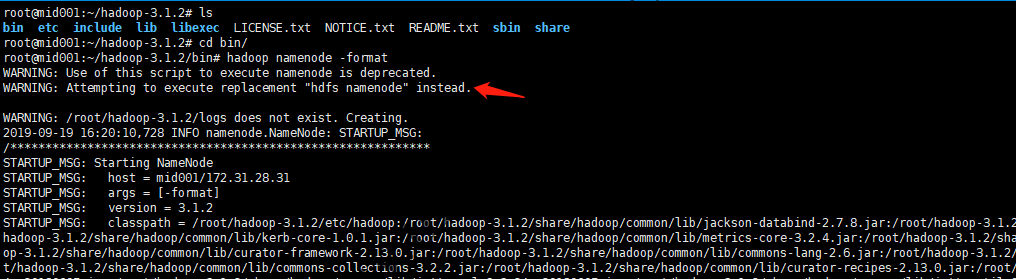
格式化HDFS的namenode
格式化完成后可以看到在所配置的dfs.namenode.name.dir目录下生成了对应的文件:
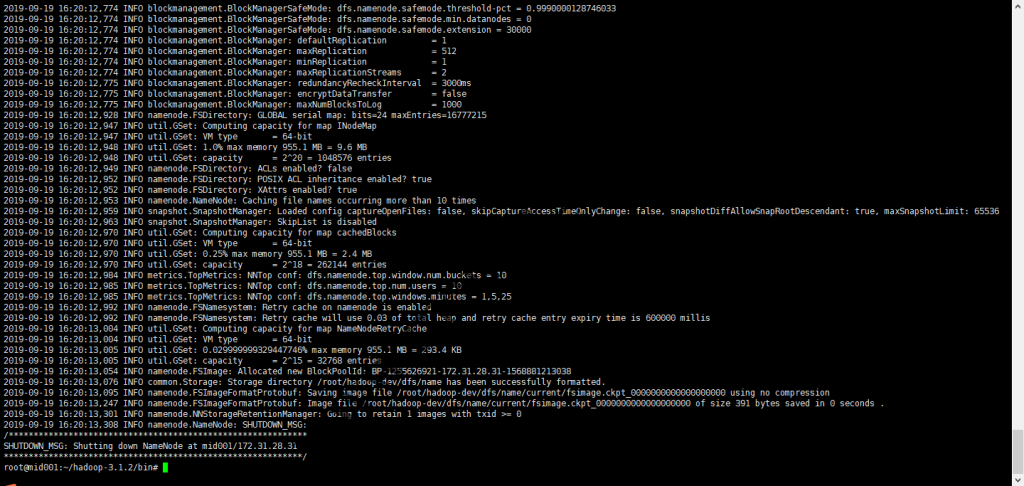
格式化HDFS的namenode完成
我们可以按照官方文档在datanode上使用 [hdfs]$ $HADOOP_HOME/bin/hdfs --daemon start namenode 启动datanode,也可以通过在namenode上配置了etc/workers之后使用sbin中的脚本管理整个集群:

修改workers配置文件
然后可以使用sbin文件夹中脚本操作整个集群,常用的主要有:
- sbin/start-all.sh 启动所有的Hadoop守护进程。包括NameNode、 Secondary NameNode、DataNode、ResourceManager、NodeManager
- sbin/stop-all.sh 停止所有的Hadoop守护进程。包括NameNode、 Secondary NameNode、DataNode、ResourceManager、NodeManager
- sbin/start-dfs.sh 启动Hadoop HDFS守护进程NameNode、SecondaryNameNode、DataNode
- sbin/stop-dfs.sh 停止Hadoop HDFS守护进程NameNode、SecondaryNameNode和DataNode
- sbin/hadoop-daemons.sh start namenode 单独启动NameNode守护进程
- sbin/hadoop-daemons.sh stop namenode 单独停止NameNode守护进程
- sbin/hadoop-daemons.sh start datanode 单独启动DataNode守护进程
- sbin/hadoop-daemons.sh stop datanode 单独停止DataNode守护进程
- sbin/hadoop-daemons.sh start secondarynamenode 单独启动SecondaryNameNode守护进程
- sbin/hadoop-daemons.sh stop secondarynamenode 单独停止SecondaryNameNode守护进程
- sbin/start-yarn.sh 启动ResourceManager、NodeManager
- sbin/stop-yarn.sh 停止ResourceManager、NodeManager
- sbin/yarn-daemon.sh start resourcemanager 单独启动ResourceManager
- sbin/yarn-daemons.sh start nodemanager 单独启动NodeManager
- sbin/yarn-daemon.sh stop resourcemanager 单独停止ResourceManager
- sbin/yarn-daemons.sh stopnodemanager 单独停止NodeManager
- sbin/mr-jobhistory-daemon.sh start historyserver 手动启动jobhistory
- sbin/mr-jobhistory-daemon.sh stop historyserver 手动停止jobhistory
但是,直接运行这些脚本是可能会报错:
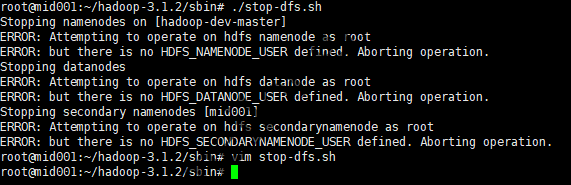
start-dfs.sh或stop-dfs.sh报错
我们分别修改start-dfs.sh或stop-dfs.sh,在其中的空白处增加:
|
1 2 3 4 |
HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root |
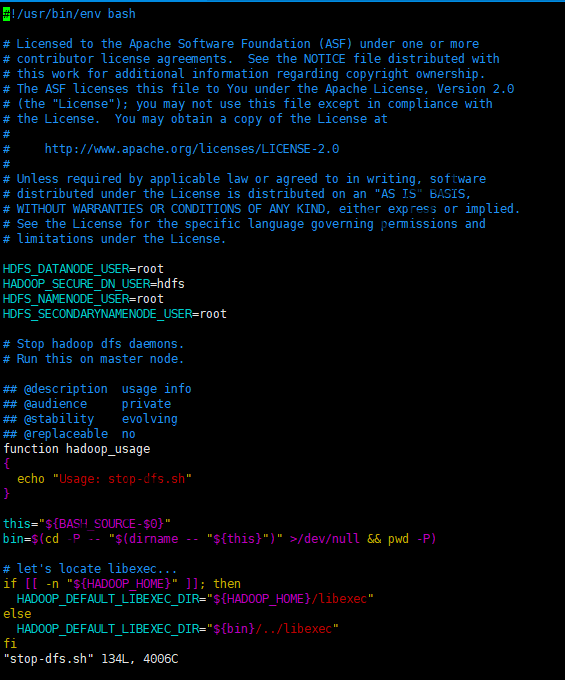
修改start-dfs.sh及stop-dfs.sh
分别修改start-yarn.sh或stop-yarn.sh,在其中的空白处增加:
|
1 2 3 |
YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root |
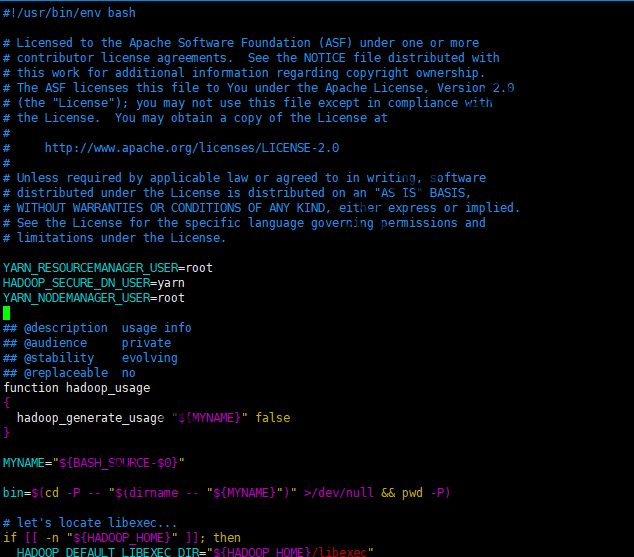
修改start-yarn.sh及stop-yarn.sh
start-dfs.sh脚本默认会向Hadoop询问namenode的主机名(同命令 hdfs getconf -namenodes),分别在这些namenode对应的每台主机上启动一个namenode和辅助namenode,再在workers中描述的每台主机上启动一个datanode。start-yarn.sh脚本类似,该脚本在本地启动一个资源管理器,再在workers中描述的每台主机上启动一个节点管理器。
运行 ./start-dfs.sh 命令后,我们就可以看到master和slave1、slave2上启动的进程了:
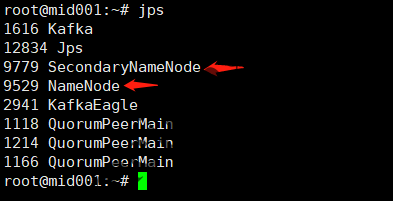
namenode进程
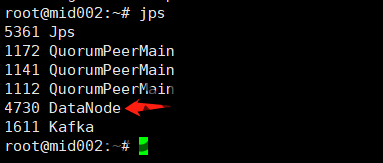
datanode进程1
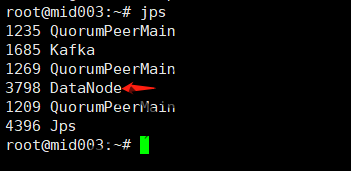
datanode进程2
在浏览器中访问hadoop-dev-master:9870,就应该可以进入到HDFS的Web管理页面了:
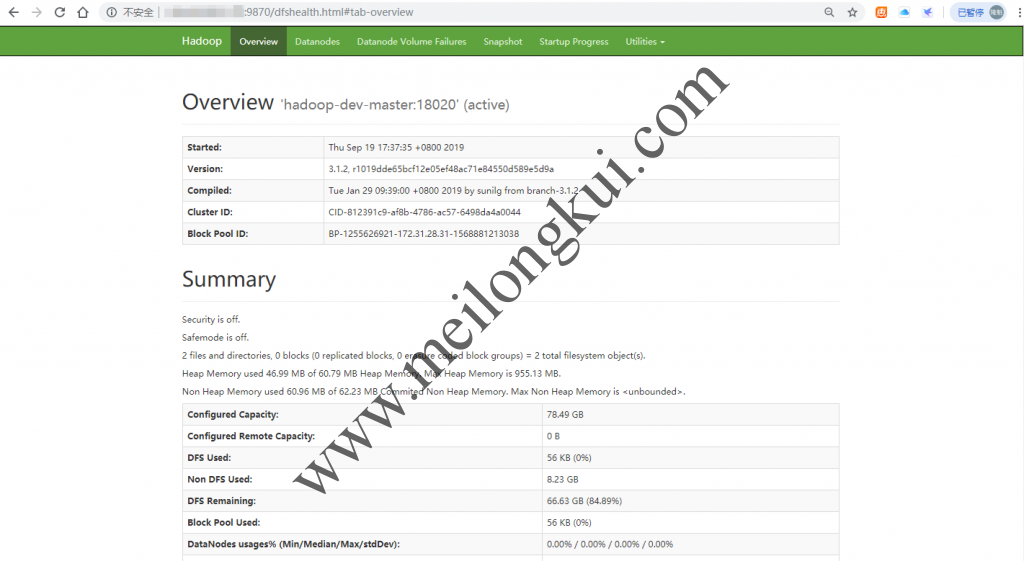
HDFS Web控制台
点击上方Datanode应该看到两个datanode:
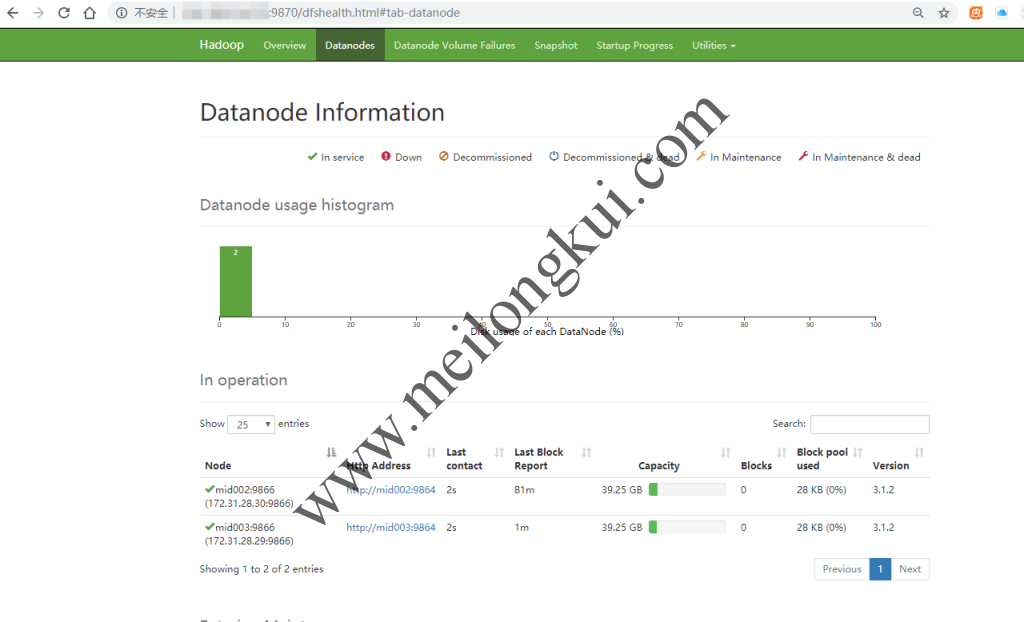
HDFS Web控制台2
此时,我们可以通过hdfs的shell命令来测试HDFS是否正常:
hdfs dfs命令
直接运行 hdfs dfs -ls 命令时会报错,这是正常的,详见参考文档2:

hdfs dfs -ls报错
hadoop fs -ls 命令的完整语法是 hadoop fs -ls [path],默认情况下当未指定[path]时Hadoop会将路径扩展为/home/[username]。这样的话,[username]就会被执行命令的Linux用户名替代,因而当执行此命令 hadoop fs -ls时Hadoop使用的路径是/home/root,但是这条路径在HDFS中不存在,因此会报错。我们可以使用 hadoop fs -ls /或使用 hdfs dfs -mkdir /user创建一个文件夹。
至此,HDFS的基础搭建就完成了。
参考文档:
1、https://hadoop.apache.org/docs/r3.1.2/hadoop-project-dist/hadoop-common/ClusterSetup.html
2、https://stackoverflow.com/questions/28241251/hadoop-fs-ls-results-in-no-such-file-or-directory
转载时请保留出处,违法转载追究到底:进城务工人员小梅 » Hadoop完全分布式集群搭建(3.1.2)-HDFS